IPF Persistent Scheduler
Introduction
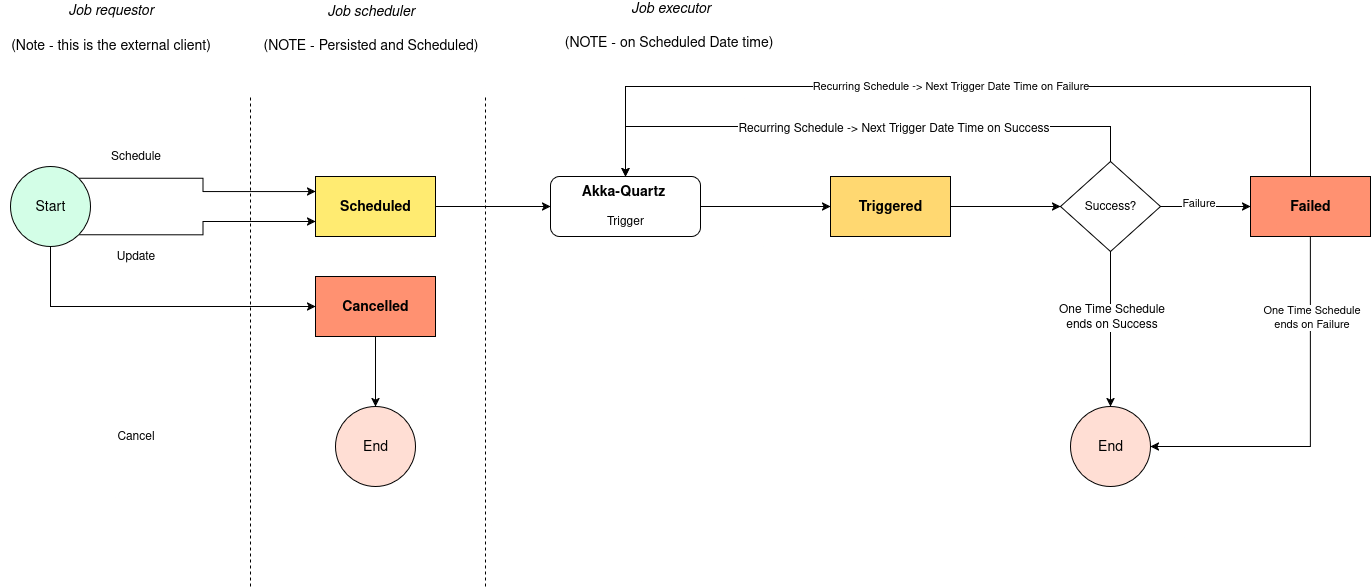
IPF’s Persistent Scheduler allows you to schedule jobs of any kind.
It is based on the Quartz scheduler and supports two types of job scheduling:
-
Recurrent jobs: defined using cron expressions, which are specialised timers that define points in time for recurring task execution.
-
One-time jobs: defined using a Java
LocalDateTimeorInstantobject for millisecond-precise, single-execution scheduling.
The scheduler also supports calendars, which can be used to exclude certain blocks of time from scheduling. This setup enables the flexible execution of both one-time and recurrent jobs. It also features a persistence layer, meaning that jobs are saved to a database, so even if an application crashes or restarts, previously scheduled jobs are recovered and continue execution as planned.
The Scheduler includes fail-safes, such as a rescheduling module that runs during startup.
This module restores all previously scheduled jobs into Quartz following a failure.
To work with the Scheduler, begin with the SchedulingModuleInterface.
Finally, the persistent scheduler is designed to be run in a Akka Cluster to ensure that jobs are scheduled across the cluster and can survive any number of node failures (including a total outage). Certain aspects like rehydration of jobs (which means reloading jobs following a failure) and processing of failed jobs are run on a Cluster Singleton to prevent duplicate processing in these scenarios.
The architecture for the scheduler is shown below: