Múltiples DC Activos - Pasivo (Esperando en Caliente), Una Base de Datos
Para propósitos de resiliencia, usted puede querer implementar múltiples instancias de su aplicación en varios centros de datos (regiones). En este escenario, usted puede tener un centro de datos "primario" que está "activo" y sirviendo tráfico, y un centro de datos "secundario" que está "pasivo" y en espera. Si el centro de datos principal falla, el centro de datos secundario tomará el control y comenzará a atender el tráfico. En este escenario, el centro de datos "activo/primario" estará sirviendo tráfico y el centro de datos "pasivo/secundario" estará en espera. Si el centro de datos principal falla, el centro de datos secundario tomará el control y comenzará a atender el tráfico. La base de datos debe ser compartida entre los dos centros de datos.
Problema
El patrón descrito anteriormente requiere que el centro de datos secundario (pasivo) tenga instancias de aplicación en ejecución (en espera), pero no deben estar comunicándose con/intentar unirse al clúster IPF en el centro de datos primario (activo) ni servir tráfico/procesar transacciones. Esto se puede lograr utilizando el MongoDB Plugin de Descubrimiento, que permite la detección de instancias de aplicación tanto en el centro de datos primario como en el secundario, asegurando que un clúster solo se forme dentro del centro de datos primario.
Nota: El complemento requiere que la base de datos esté compartida entre los dos centros de datos.
A continuación se proporciona una guía sobre cómo configurar el complemento.
Paso 0: Agregue la dependencia
Añada el akka-discovery-mongodb-management dependencia a la pom.xml, que contiene la lógica del plugin y algunos puntos finales útiles para gestionar el clúster.
<dependency>
<groupId>com.iconsolutions.ipf.core.discovery</groupId>
<artifactId>akka-discovery-mongodb-management</artifactId>
</dependency>Paso 1: Configure el complemento
Toda la configuración descrita en esta sección Configure el arranque del clúster con MongoDB descubrimiento debe ser añadido al archivo de configuración, solo enumeraremos las cosas que son diferentes de la configuración predeterminada.
Así que en todos los nodos en DC 1 (Activo) debemos especificar:
akka.discovery.akka-mongodb.enabled = true
akka.discovery.akka-mongodb.collection = "akka-discovery-mongodb-dc1"Y en todos los nodos en DC 2 (Pasivo) debemos especificar:
akka.discovery.akka-mongodb.enabled = false
akka.discovery.akka-mongodb.collection = "akka-discovery-mongodb-dc2"El nombre de la colección debe ser diferente para cada centro de datos, ya que la base de datos es compartida.
Esto resultará en la topología a continuación:
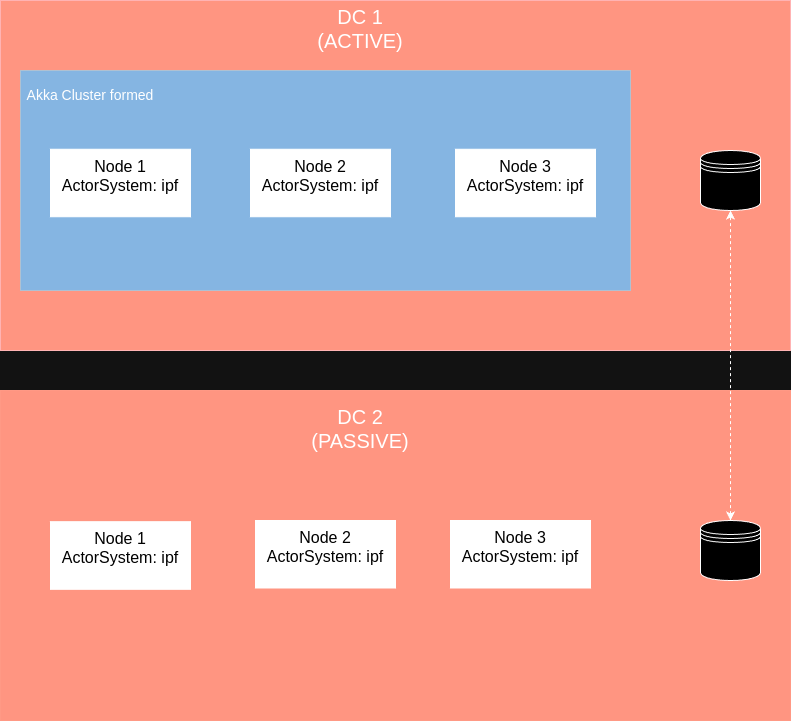
Verifique esto pulsando el Akka Cluster de Gestión HTTP Gestión de /cluster/members URL para observar la configuración correcta de los clústeres en cada DC.
Paso 2: Desactive nodos en el DC activo
| Solo debe tener un clúster de akka activo a la vez. Si este no es el caso, todos los clústeres activos intentaré procesar las mismas transacciones. Esto resultará en resultados de transacción impredecibles. |
Si el clúster primario sigue activo, pero desea cambiar el procesamiento al clúster pasivo, debe Detenga/pasive el clúster activo de Akka antes de activar el clúster pasivo.
Esto puede hacerse de la siguiente manera:
Paso 2.1: Marque los nodos como no activos
Marque los nodos akka activos como inactivos a través del /discovery/cluster-status punto final.
POST http://hostname:server_port/discovery/cluster-status
Accept: application/json
{
"active": false
}Esto marca los nodos activos como inactivos, pero no detiene el procesamiento. Este valor se persiste y se utiliza como el valor de configuración para la propiedad akka.discovery.akka-mongodb.enabled, si la aplicación se reinicia. Al iniciar la aplicación, esta intentará obtener el valor persistido. Si el valor persistido no existe, se utilizará el valor del archivo de configuración.
Paso 2.2: Detener el procesamiento de transacciones
Para detener el procesamiento de transacciones, los nodos en el clúster activo deben ser apagados o reiniciados de manera controlada. Si se reinician, formarán un clúster pasivo, porque se cambió la configuración de la propiedad akka.discovery.akka-mongodb.enabled a falso y persistido. Después de que el nodo se reinicie, leerá el nuevo valor de configuración y no formará un clúster activo de akka.
Akka HTTP La gestión puede utilizarse para apagar de manera ordenada todos los nodos:
Puede obtener una lista de todos los nodos akka con
GET http://hostname:akka_management_port/cluster/membersPara todos los nodos recuperados de la solicitud anterior (alcanzables y no alcanzables), el apagado puede ser triggered con
DELETE http://akka_node_hostname:akka_management_port/cluster/members/<akka_node_address>Más sobre Akka Los endpoints de gestión HTTP se pueden encontrar aquí.https://doc.akka.io/libraries/akka-management/current/cluster-http-management.html#api-definition[Definición de API]
Paso 3: Active nodos en DC pasivo
| El 'clúster previamente activo' debe ser deshabilitado/apagado/pasivado antes de que el clúster pasivo sea habilitado. |
Cuando el DC primario falla (o ha sido apagado/desactivado), los nodos en el DC secundario deben ser activados. Esto puede hacerse a través de /discovery/cluster-status punto final.
POST http://hostname:server_port/discovery/cluster-status
Accept: application/json
{
"active": true
}Esto activa los nodos en el DC pasivo, y comenzarán a atender tráfico. El valor de configuración, Para la propiedad akka.discovery.akka-mongodb.enabled, se persiste y se utiliza si la aplicación se reinicia. Al iniciar la aplicación, esta intentará obtener el valor persistido. Si el valor persistido no existe, se utiliza el valor del archivo de configuración.
Paso 4: Kubernetes Configuración de Verificación de Salud
Cuando la sonda de disponibilidad está configurada con /actuator/health/readiness or /actuator/health puntos finales, los pods en el clúster pasivo-que actualmente no está procesando trabajo-se reiniciará repetidamente ya que el punto final de actividad seleccionado nunca devolverá un éxito.
Esto podría resultar en el resultado indeseable de que se envíe una solicitud de activación de clúster entrante cuando los nodos se están reiniciando, lo que provoca que se pierda la solicitud de activación.
Este problema puede ser mitigado configurando una prueba de inicio. La prueba de inicio puede ser configurada para utilizar el Akka Gestión de Http
punto de verificación de salud /health/ready.
Esta verificación de salud solo está al tanto de Akka estado del clúster (y no está al tanto del estado de los conectores IPF, MongoDB estado de conexión, etc.)
Esto es lo que necesitamos en este caso. La sonda de inicio esperará (durante un período de tiempo configurado) por el Akka clúster a ser formado.
Cuando esto esté hecho, se entregará la supervisión de la aplicación a las sondas de disponibilidad y de actividad.
Si el Akka el clúster no se ha formado (en el período de tiempo configurado), la aplicación será reiniciada y se realizará la prueba de inicio
comenzará a monitorear la aplicación recién iniciada desde el principio.
La sonda de arranque fue probada durante períodos que oscilan entre 1h y 24h. La elección de un intervalo apropiado queda a discreción del usuario según sus requisitos específicos.
A continuación se proporciona un ejemplo de la configuración de las sondas de verificación de salud de K8S:
livenessProbe:
failureThreshold: 6 # 30s
httpGet:
path: /actuator/health/readiness
port: http
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
failureThreshold: 3 # 15s
httpGet:
path: /actuator/health/readiness
port: http
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 2
startupProbe:
failureThreshold: 720 # 1h
httpGet:
path: /health/ready
port: akka-management
scheme: HTTP
initialDelaySeconds: 15
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 2