Monitoreo y Observabilidad
La estrategia sobre IPF para el monitoreo y la observabilidad se logra mediante la utilización de un paradigma impulsado por eventos, una categorización estricta del comportamiento de la aplicación y la extensibilidad para exponer estos datos a través de canales apropiados, con las mejores herramientas.
Monitoreo de IPF application Los servicios pueden realizarse de tres maneras principales:
-
HTTP APIs
-
Métricas de series temporales a través de Prometheus y Grafana
-
Registro de aplicaciones
Fuera de Alcance:
-
Monitoreo del rendimiento de aplicaciones (APM)- Esto es algo a considerar si dicho software está disponible en el customer’s site. El software APM como Dynatrace o AppDynamics puede ayudar a diagnosticar problemas potenciales antes de que se materialicen.
-
Monitoreo de Infraestructura, p. ej., Corredores, contenedores
Definiciones
El " IPF application "en realidad está compuesto por múltiples paquetes de software en tiempo de ejecución. Esta sección describirá la terminología que se utilizará en este documento:
| Componente | A veces conocido como | Descripción | Necesita estar en Akka¿Agrupar con otros nodos similares? |
|---|---|---|---|
Servicios de Pago (Personalizados) |
Escriba al lado |
El conjunto de payment flows que el cliente ha definido. Puede haber múltiples de estos que representan diferentes conjuntos de flujos (por ejemplo, transferencia de crédito, recuperación, servicio de valor añadido). |
Sí |
CSM Service |
CSM Pack,Scheme Pack |
Un adaptador para un proveedor de pagos, como un esquema de pago, billetera, etc. |
No |
Servicios de Soporte |
Servicio de Notificación |
Procesamiento adicional de eventos a sistemas de terceros. |
Sí |
Servicio Individual APIs(HTTP)
Hay ciertos HTTP APIs que están habilitados por defecto y que pueden ser interrogados cuando la aplicación está en ejecución, cada uno sirviendo a un propósito específico.
Aquí tiene un resumen de esos APIs y los elementos de configuración que establecen sus nombres de host y puertos:
| ¿Qué es? | ¿Qué hace? | Caso de uso de ejemplo | Referencia de API (o similar) | Nombre de host predeterminado | Puerto predeterminado | Anular variable de entorno del host | Variable de entorno de anulación de puerto | Disponible en |
|---|---|---|---|---|---|---|---|---|
Spring Boot Actuador API |
Spring Boot métricas de estilo para el JVM, propiedades de configuración de Spring,beans, salud |
Para verificar la versión de las bibliotecas activas |
|
|
|
|
|
|
Cluster de Gestión de Akka HTTP API |
Información sobre el funcionamiento actual Akka clúster para fines de depuración |
Para verificar el estado del clúster y gestionar manualmente los nodos. |
(el resultado de |
|
|
|
|
Spring Boot Actuador API
Utilice esto API para consultar sobre la Spring ApplicationContext que actualmente se está ejecutando en este nodo en particular. Algunos endpoints interesantes de Spring Actuator para IPF:
-
conditionsVerifique que el lado de escritura y lectura de la aplicación se haya configurado correctamente en los nodos relevantes. -
env: Muestre las variables de entorno para verificar que las sobreescrituras son correctas -
health: Útil para sondas de actividad y similares -
info: Información general de la aplicación (también útil para las pruebas de actividad)
Hay más puntos finales disponibles.
Visite el Spring Boot Consulte el enlace del actuador en la tabla anterior para ver todos los detalles.
Además, tenga en cuenta esto
sección particular sobre cómo habilitar y deshabilitar endpoints de Actuator particulares MANAGEMENT_ENDPOINT_X_ENABLED donde X
es la parte del Actuador relevante).
Para obtener información sobre cómo configurar TLS para los puntos finales del Actuator, consulte esta sección.
Akka Cluster HTTP Gestión
Este API permite al usuario interactuar con el IPF subyacente Akka cluster utilizando un HTTP interfaz.
El uso principal para esto API es verificar el estado del clúster. Los componentes de implementación del cliente IPF requieren que todos los nodos de "escritura" que sirvan al mismo conjunto de flujos (por ejemplo, transferencia de crédito, recuperación, pago de billetera digital) estén en un Akka agrúpese. Si este no es el caso, no se aceptará nuevo trabajo para evitar la pérdida de transacciones.
El clúster encuentra otros nodos similares por sí mismo, pero en caso de que la aplicación no parezca estar consumiendo ningún trabajo nuevo, este debe ser el primer punto de consulta para asegurar que el clúster se encuentre en un estado válido y que la aplicación no esté en un "cerebro dividido" (creándose múltiples nodos en clústeres separados).
Las situaciones de cerebro dividido pueden resolverse utilizando el Akka Resolutor de Cerebro Dividido. Se puede encontrar más información sobre este tema en el Sitio web de Akka.
El Akka Cluster HTTP El endpoint de gestión también permite operaciones de actualización.
Si este comportamiento no es deseado, establezca el
AKKA_MANAGEMENT_READ_ONLY`variable de entorno para `true para habilitar el modo de solo lectura donde la información del clúster solo puede ser recuperada pero no actualizada.
Configuración de TLS para Akka La gestión es la misma que la de Spring Boot, pero el server or management.server los prefijos son reemplazados por akka.management.
Por ejemplo, para establecer la ruta del almacén de claves, la propiedad sería
akka.management.ssl.keystore`or `AKKA_MANAGEMENT_SSL_KEYSTORE(the Spring Boot equivalente siendo server.ssl.keystore
o SERVER_SSL_KEYSTORE).
Métricas de Series Temporales
Las métricas se exponen a través de una Prometheus HTTP servidor que es interrogado en un intervalo de tiempo determinado por Prometheus, y visualizado utilizando herramientas como Grafana y Kibana.
El componente AlertManager realiza una agregación configurable de eventos basada en umbrales y condiciones para traducir este comportamiento del sistema en algo que puede requerir acción por parte de un Operador.
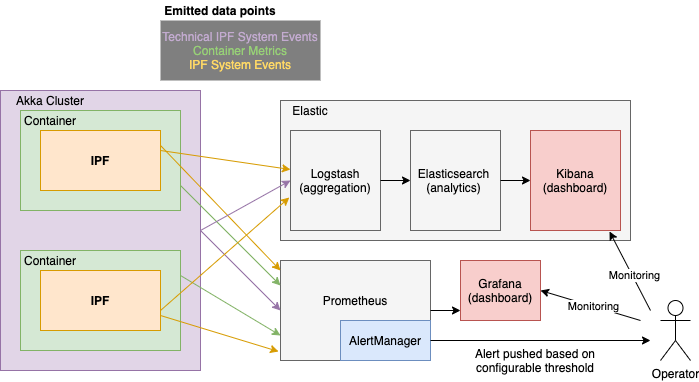
Métricas de Aplicación Relevantes
Las métricas agregadas a nivel de aplicación también se exponen con el mismo mecanismo:
| Nombre de la métrica | Tipo | Descripción | Información del evento | Fuente | ||
|---|---|---|---|---|---|---|
|
Histograma |
Tiempo en segundos que toma la ejecución de un flujo |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Número total de invocaciones |
mismos etiquetas que se utilizan en ipf_comportamiento_latencia_final_a_final_segundos_cubo |
Spring Actuator (TCP/8080) |
||
|
Contador |
Tiempo total gastado por todas las invocaciones |
mismos etiquetas que se utilizan en ipf_comportamiento_latencia_final_a_final_segundos_cubo |
Spring Actuator (TCP/8080) |
||
|
Histograma |
Tiempo dedicado por los flujos en ese estado |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Número total de llamadas a ese estado |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Tiempo dedicado por todas las llamadas a ese estado |
|
Spring Actuator (TCP/8080) |
||
|
Calibrador |
Número de flujos activos por estado |
|
Spring Actuator (TCP/8080) |
||
|
Histograma |
Tiempos desde el momento en que IPF recibe un comando hasta que se completan todos los efectos secundarios. |
Segmentado por comportamiento, nombre del comando, estado anterior, estado resultante, resultado de la llamada (éxito, fracaso)
|
Spring Actuator (TCP/8080) |
||
|
Histograma |
Tiempo para realizar una llamada a IPF, incluyendo el tiempo de persistencia del evento, la ejecución de todos los efectos secundarios y los posibles reintentos. |
Segmentado por comportamiento, nombre del comando, resultado de la llamada (éxito/fallo)
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Se han creado (iniciado) un número de transacciones. |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Número de transacciones que han alcanzado un estado terminal (final) |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Número de flujos que han generado un evento de sistema por tiempo de espera |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Se genera cuando el dominio IPF invoca una acción en un sistema externo. |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Se genera cuando una acción invocada por IPF no ha recibido una respuesta dentro del tiempo de espera configurado. |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Se genera cuando un Dominio Event ha sido persistido con éxito |
|
Spring Actuator (TCP/8080) |
||
|
Contador |
Se genera cuando el dominio IPF recibe un comando que no puede ser manejado en el estado actual del agregado. |
|
Spring Actuator (TCP/8080) |
||
|
Histograma |
que registra la duración entre el momento en que un domain event ha sido creado y el tiempo que ha sido enviado a ODS; las duraciones serán sensibles a la desviación temporal entre los servidores, por lo que deben ser tratadas únicamente como estimaciones. |
Spring Actuator (TCP/8080) |
|||
|
Contador |
Conteo del número total de domain events enviado a ODS |
||||
|
Contador |
Tiempo total empleado para enviar domain events to ODS |
|
Spring Boot Tableros de control
Básico JVM métricas a través de la prometheus Spring Boot Punto final del actuador.
Hay varios paneles que pueden ser utilizados para visualizar estos datos, pero recomendamos este from the Grafana colección de paneles de control.
Akka Tableros de control
Hay algunas soluciones listas para usar. Grafana métricas que están disponibles para Akka, documentado y disponible para descargar aquí. Lo interesante Akka tableros de control a tener en cuenta-en lo que respecta a IPF - are:
-
Evento Sourced Behaviours: Métricas sobre eventos y comandos que están siendo procesados por IPF flows
-
Akka Streams y Akka Streams Métricas de rendimiento del procesamiento de flujos de conectores
Tableros Específicos de IPF
También hay algunos custom Tableros específicos de IPF que están disponibles:
| Nombre | Descripción | Datos Requeridos |
|---|---|---|
|
Estadísticas por conector sobre el número de solicitudes enviadas, recibidas y los tiempos de respuesta promedio por conector. |
|
|
Estadísticas por flujo sobre cuánto tiempo tardan los flujos en ser procesados desde la iniciación hasta que alcanzan un estado final. |
|
|
Informa estadísticas sobre los interruptores de circuito del conector utilizando métricas definidas en Resilience4J. |
|
|
Proporciona algunas estadísticas sobre el JVM, por ejemplo, la memoria heap, por pod en el clúster. Para un panel de control más detallado, consulte |
|
|
Informes sobre cualquier métrica de solicitud/respuesta de CSM simuladores que están desplegados en el clúster. |
Requiere un |
|
Informes sobre una amplia gama de métricas de servicio de aplicaciones (MongoDB/Akka..) para determinar la salud general del ecosistema de IPF y ayudar a identificar si ha habido alguna degradación del rendimiento a lo largo del tiempo. |
|
|
Estadísticas relacionadas con el ODS servicio de ingestión que informa sobre cualquier retraso en la ingestión de datos, así como métricas relacionadas con Kafka/MongoDB. |
Se asume que el nombre del pod es Kafkase asume que el grupo de consumidores para la entrada se llama Kafkael tema de salida se asume que se llama |
|
Informes sobre estadísticas basadas en métricas de flujo para mostrar transacciones en estados completados o no completados. |
El nombre del estado de finalización se asume que termina con la palabra |
|
Informes sobre Event Sourced Behaviours métricas de acción y entrada de (ESBs) que proporcionan la tasa de ejecución entre estas funciones. |
|
|
Proporciona estadísticas detalladas sobre el JVM de las métricas proporcionadas por el actuador de Spring. |
|
|
Proporciona métricas generales y por conector sobre los tiempos de solicitud y respuesta. |
Requiere un |
Ejemplo práctico de uso de PromQL para generar un gráfico personalizado
Requisito
Un gráfico circular para representar todos los CSM estados de finalización de todas las transacciones que ocurrieron en este día calendario y que tomaron menos del SLA de 5 segundos.
Paso 1 - Elección de Métrica
Primero debe encontrar la métrica más cercana que proporcione los datos requeridos, en este caso la ipf_behaviour_end_to_end_latency_seconds los datos del histograma deben funcionar.
sum by(event) (
increase(
ipf_behaviour_end_to_end_latency_seconds_bucket{type="CSM_STATES_ONLY", service=~".*creditor.*", le="5.0"}[15m]
)
)Esta consulta devolverá el número de estados completados en intervalos de 15 minutos agrupados por event
-
prometheus.io/docs/prometheus/latest/querying/functions/#increase
increase]- calcula el aumento en la serie temporal en el vector de rango -
sum- calcula el total en la serie temporal
Se pueden encontrar más funciones de PromQL que pueden ser utilizadas.https://prometheus.io/docs/prometheus/latest/querying/functions[aquí].
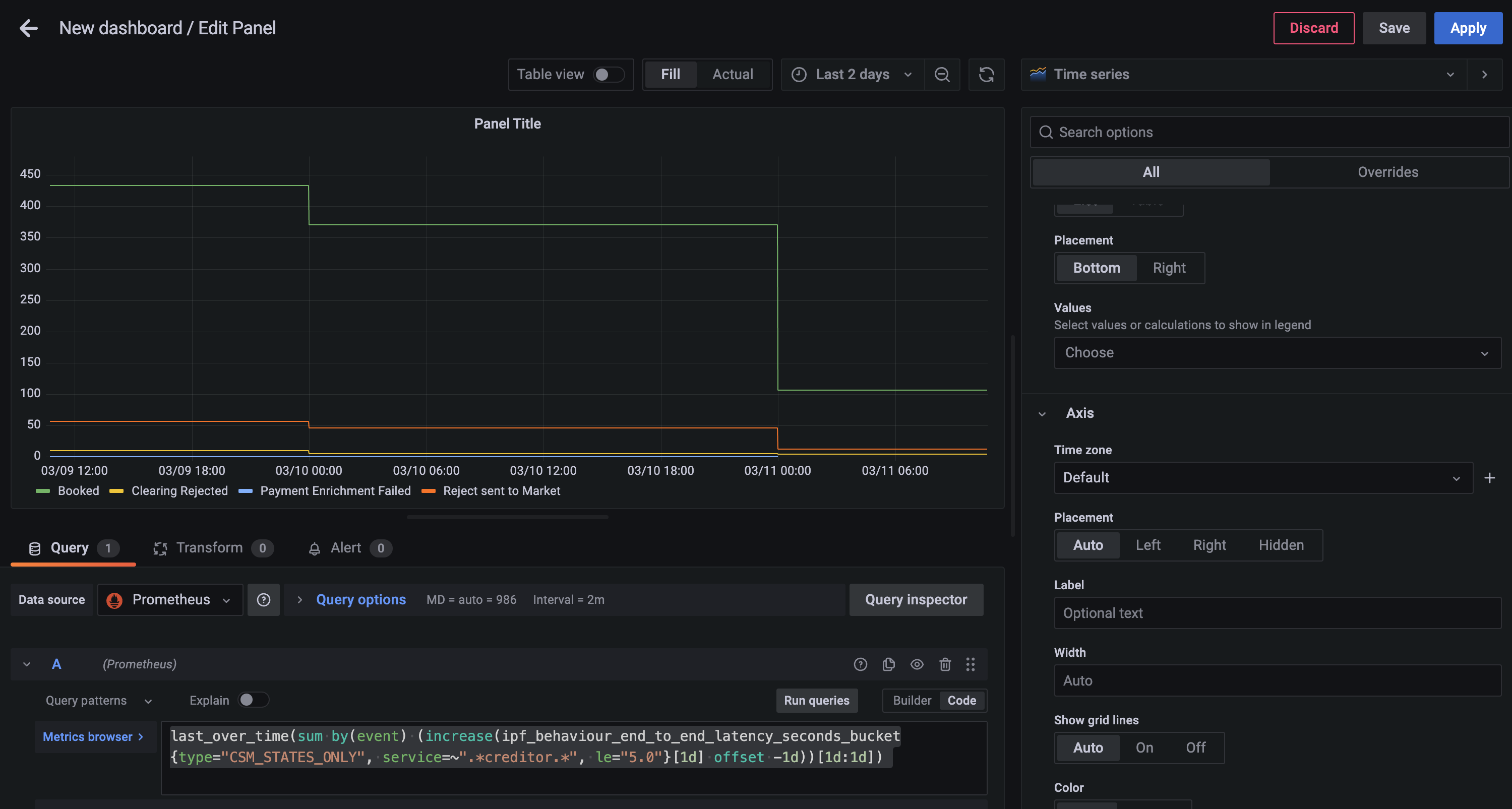
Paso 2 - Agrupación en Días
Ahora puede crear un diario hoy con la siguiente consulta
last_over_time(
sum by(event) (
increase(
ipf_behaviour_end_to_end_latency_seconds_bucket{type="CSM_STATES_ONLY", service=~".*creditor.*", le="5.0"}[1d] offset -1d
)
)
[1d:1d]
)-
prometheus.io/docs/prometheus/latest/querying/functions/#aggregation_over_time
last_over_time]- el valor de punto más reciente en el intervalo especificado
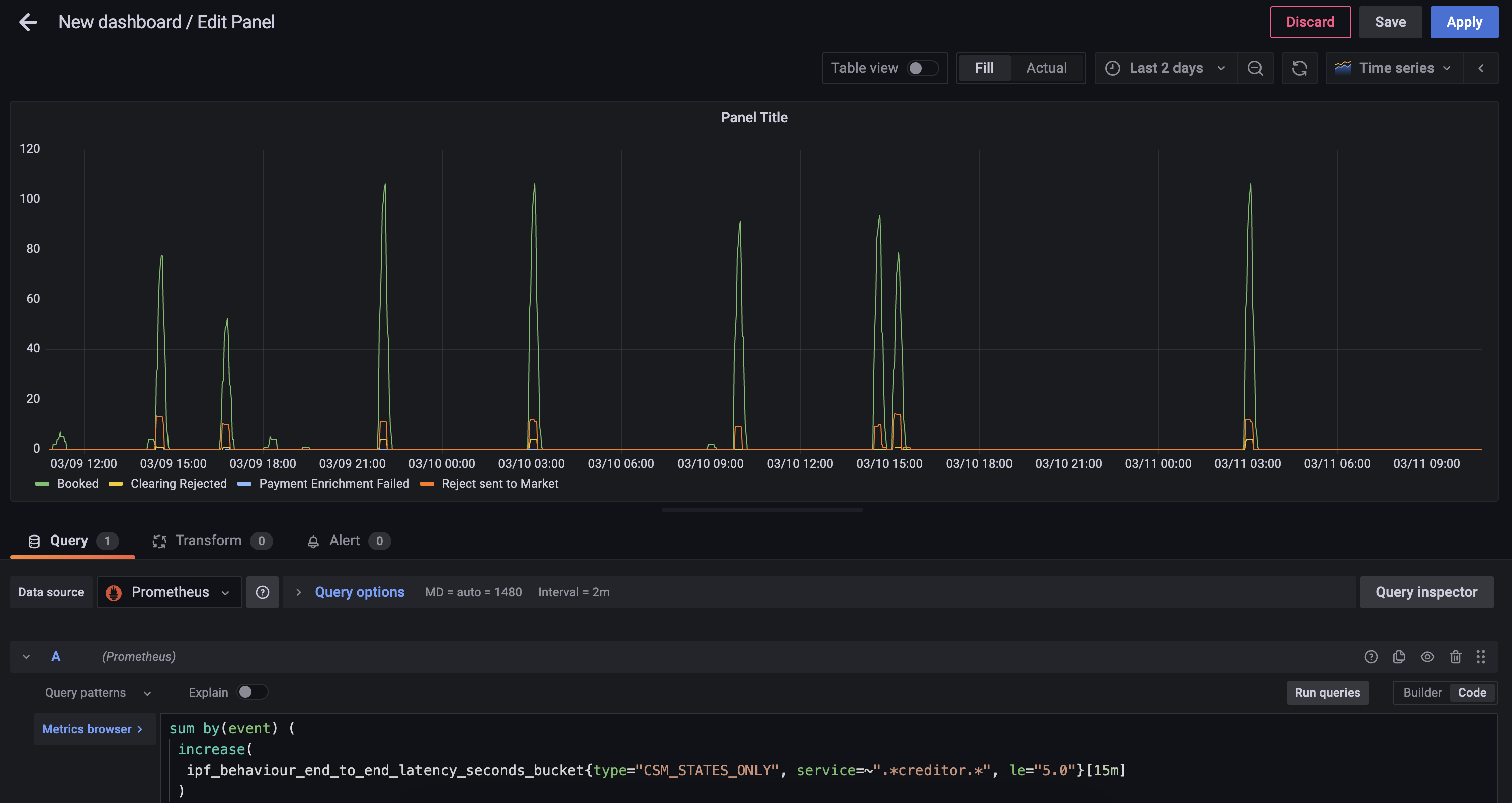
Paso 3 - Limitar a un Solo Día
Alterar el panel de Query options para añadir un relative time of now/d
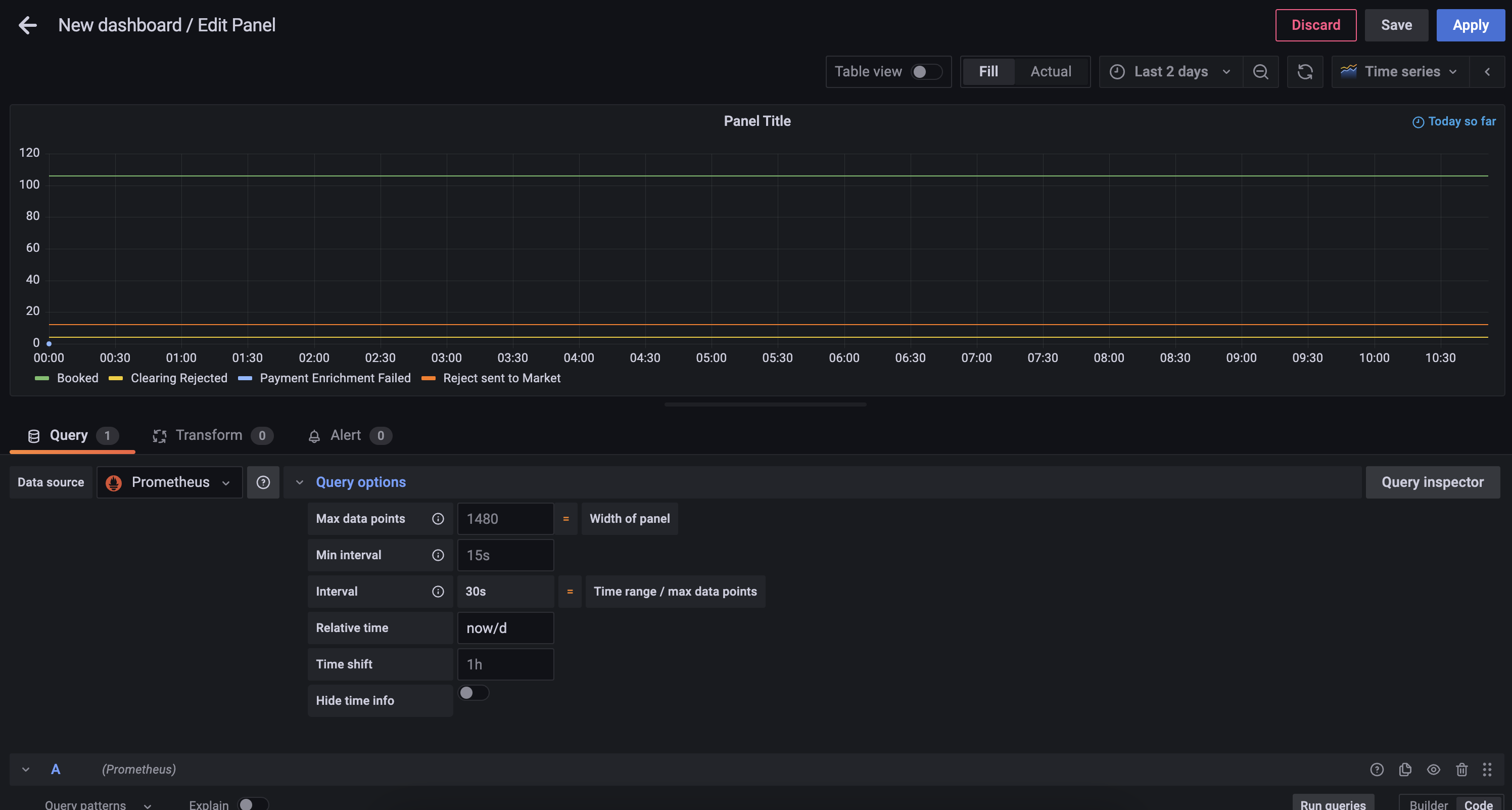
Paso 4 - Cambie el Estilo del Gráfico
Utilizando el selector de visualización en el lado derecho, elija el Pie Chart opción, y altere el Title to Calls to Scheme.
También podrá añadir los siguientes cambios:
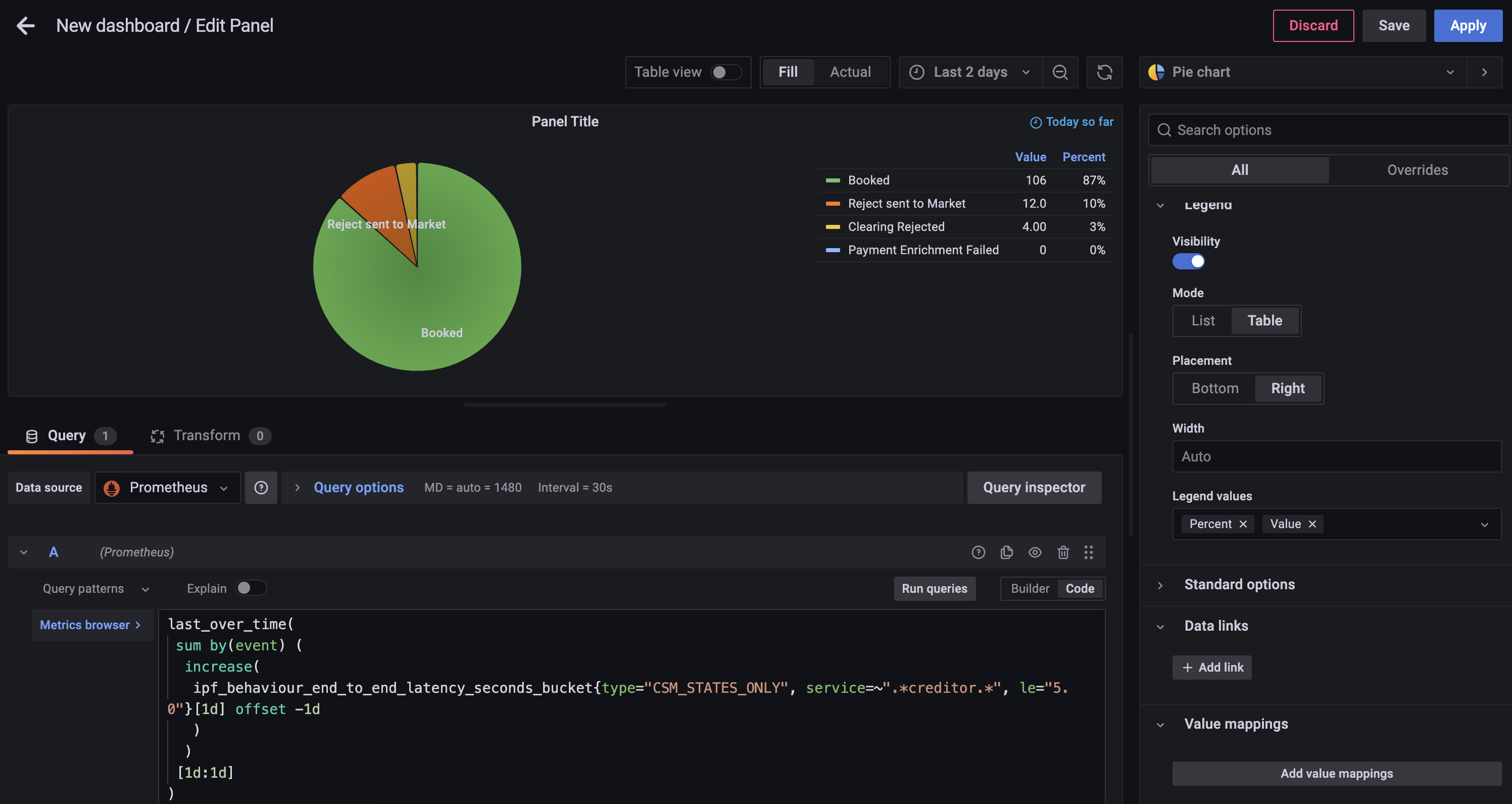
-
Añada etiquetas de gráfico de sectores de
Name -
Cambie el modo de leyenda a
Table, establezca la colocación enRighty añada Valores de Etiqueta dePercentyValue
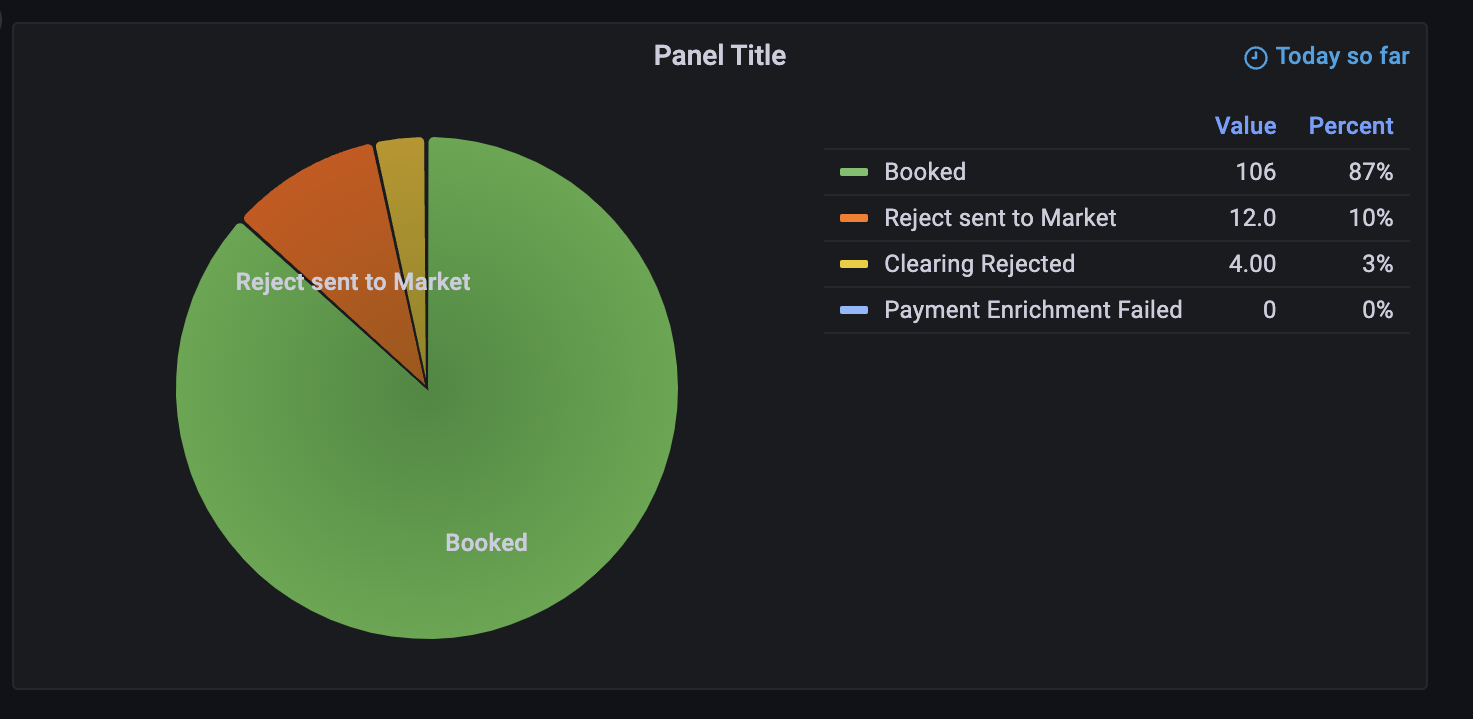
Ahora puede guardar el panel, que luego se verá algo como
Configuración del Exportador
Spring BootLas métricas del actuador se exponen a través del mismo actuador. HTTP servidor documentado arriba. Consulte arriba para saber cómo cambiar el host y el puerto del Actuator.
Ambos Akka y específico de IPF Prometheus las métricas están disponibles en el mismo Prometheus servidor web de exportador, que por defecto está configurado para escuchar en todas las interfaces (0.0.0.0) y puerto 9001.
Para cambiar estos detalles, las variables de entorno relevantes son:
-
CINNAMON_PROMETHEUS_HTTP_SERVER_HOST -
CINNAMON_PROMETHEUS_HTTP_SERVER_PORT
Si se cambian estas propiedades, recuerde también cambiar el Prometheus lado para que Prometheus puede recopilar datos de series temporales de la(s) dirección(es) correcta(s).
Registro
IPF utiliza Logback para la configuración de registro. Esto permite al usuario configurar una instalación de registro que puede reflejar la de otras aplicaciones desarrolladas dentro de la organización y hacer que IPF informe los datos de registro de la misma manera.
Este documento explicará algunas configuraciones de registro típicas que pueden utilizarse para generar datos de registro de diversas maneras.
Para todas las configuraciones, el archivo de configuración de Logback debe estar montado en el classpath de la aplicación.
Para una imagen construida con Icon, esto siempre está disponible en /[name of container]/conf.
Así que si el contenedor se llama credit-transfer, entonces la configuración de Logback puede ser montada en /credit-transfer/conf/logback.xml.
Opción 1: Elasticsearch/Logstash/Kibana
Una pila popular en la industria es ELK: una combinación de Elasticsearch, Logstash (y/o Beats) y Kibana. Anteriormente se conocía como la pila ELK, pero con la introducción de Beats, Elastic ha estado promoviendo la denominación más genérica de "Elastic Stack" para esta configuración.
De cualquier manera, la configuración se ve así:
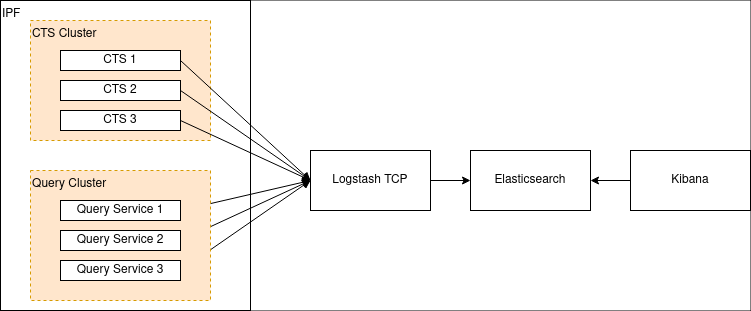
Primero necesitamos configurar Logstash para que escuche en un puerto TCP. Aquí tiene un ejemplo de cómo configurar eso en Logstash:
input {
tcp {
port => 4560
codec => json_lines
}
}Esto hace que Logstash escuche en el puerto 4560 por líneas de JSON separado por el carácter de nueva línea \n.
El appender Logback de Logstash hace esto por nosotros y puede ser configurado de la siguiente manera:
<? xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="stash" class="net.logstash.logback.appender. LogstashAccessTcpSocketAppender">
<destination>127.0.0.1:4560</destination>
<encoder class="net.logstash.logback.encoder. LogstashAccessEncoder" />
</appender>
<appender-ref ref="stash" />
</configuration>Esto configurará IPF application registros que deben ser enviados a Logstash. Configurar Logstash para conectarse a Elasticsearch (y Kibana a Elasticsearch) está fuera del alcance de este documento, pero puede encontrarse en el sitio web de Elastic.https://www.elastic.co/start[aquí].
Más ejemplos, incluyendo:
-
Configurando TLS sobre la conexión TCP, y;
-
Una variante UDP del appender
Se puede encontrar en la página de GitHub del appender Logback de Logstash.https://github.com/logstash/logstash-logback-encoder[aquí].
Configurando un Appender de Logstash para System Events
Si desea agregar eventos del sistema IPF, considere utilizar el com.iconsolutions.payments.systemevents.utils. Slf4jEventLogger
que reenvía todos los eventos del sistema recibidos a un apéndice.
Esto puede ser utilizado en conjunto con este appender de Logstash para enviar eventos del sistema a un agregador como Elasticsearch, como se mencionó anteriormente.
Aquí tiene un ejemplo de configuración de Logback que toma Slf4jEventLogger eventos y los envía a nuestro STASH appender:
<logger name="com.iconsolutions.payments.systemevents.utils. Slf4jEventLogger" level="DEBUG" additivity="false">
<appender-ref ref="STASH"/>
</logger>Opción 2: Splunk
Aparte de una configuración específica como la mencionada anteriormente, una verdadera aplicación de doce factores debe generar sus registros.- sin búfer-to
stdout, y esto puede ser analizado por software como Splunk.
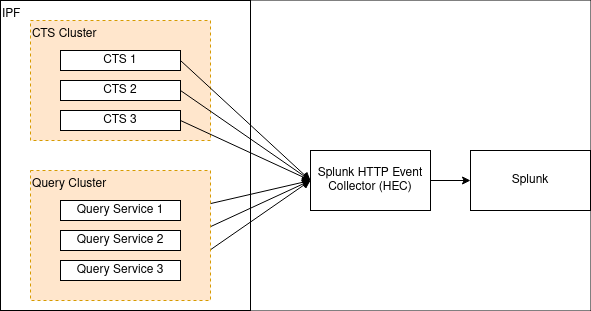
Splunk proporciona un HTTP apéndice para Logback. Esto está documentado aquí. Ese documento también describe algunas consideraciones de rendimiento para el registro con HTTP, y también un appender TCP que puede ser utilizado en lugar de HTTP.
La plantilla de Logback mencionada en ese documento se puede encontrar aquí.
Hay tres campos obligatorios:
-
url: La URL de Splunk a la que debe reenviar -
token: El token proporcionado por Splunk para la autenticación y autorización -
index: El índice de Splunk (repositorio) para almacenar estos datos de registro
Opción 3: Archivos (No Recomendado)
Registrar en un archivo rompe los principios nativos de la nube sobre no hacer suposiciones acerca de un sistema de archivos subyacente. Los registros deben ser tratados como flujos de datos en lugar de archivos que necesitan mantenimiento. Utilice este enfoque solo como último recurso cuando no sea absolutamente posible utilizar un enfoque más moderno para el registro. Para más información, consulte XI. Registros sobre la aplicación de Doce Factores. |
Es posible especificar un appender de archivo Logback normal.
Un típico logback.xml podría verse así:
<? xml version="1.0" encoding="UTF-8" scan="true"?>
<configuration>
<jmxConfigurator />
<appender name="FILE"
class="ch.qos.logback.core.rolling. RollingFileAppender">
<file>/opt/ipf/logs/credit-transfer-service.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling. FixedWindowRollingPolicy">
<fileNamePattern>/opt/ipf/logs/credit-transfer-service.log.%i</fileNamePattern>
<minIndex>1</minIndex>
<maxIndex>20</maxIndex>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling. SizeBasedTriggeringPolicy">
<maxFileSize>50MB</maxFileSize>
</triggeringPolicy>
<encoder>
<pattern>%date{yyyy-MM-dd} %d{HH:mm:ss. SSS} %-5level %X{traceId} %logger{36} %X{sourceThread} %X{akkaSource} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="FILE" />
</root>
</configuration>Este archivo crea la siguiente configuración:
-
El archivo de registro se analiza en busca de cambios en vivo cada minuto (
scan="true"). -
La configuración de registro puede ser modificada en vivo con JMX. Más información sobre esto está disponible.http://logback.qos.ch/manual/jmxConfig.html[aquí].
-
Registro de archivos en
/opt/ipf/logs/credit-transfer-service.log. -
Archivos transferidos a
/opt/ipf/logs/credit-transfer-service.log.n, donde n es un número entre 1-20, y se reinicia cuandocredit-transfer-service.logllega a 50 MB. Tenga en cuenta que solo se conservarán 20 de dichos archivos (es decir, un total de 1 GB de datos de registro).
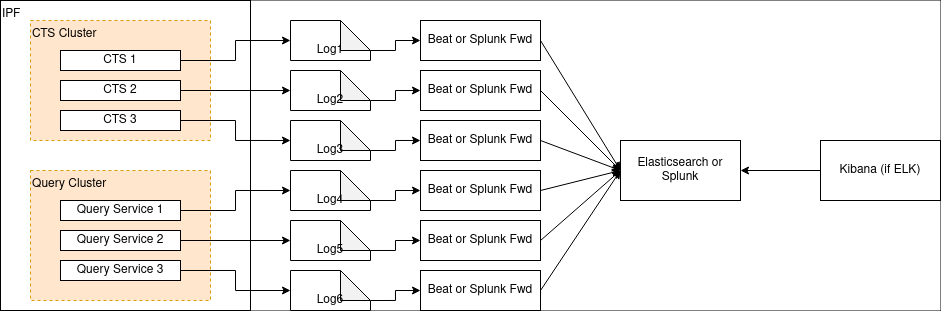
Este archivo también puede ser extraído por un marco como Splunk forwarder or Beats como se muestra en el diagrama a continuación:
System Events
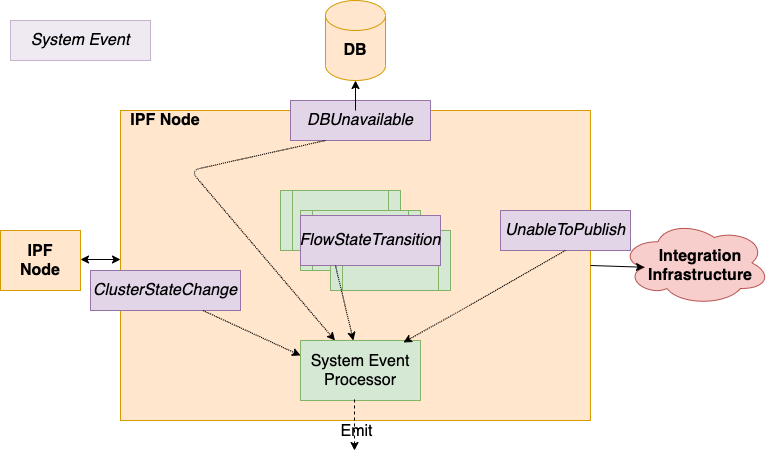
¿Qué son IPF System Events
-
IPF applications están respaldados por un System Event marco, proporcionando capacidades de pub/sub entre los componentes de la aplicación.
-
Jerárquico, extensible, versionado, catalogado. Todas las áreas de aplicación: Técnica, Funcional y Ciclo de Vida. Todos los eventos incluyen propiedades comunes: ubicación de origen, hora de creación, nivel, tipo, contexto de asociación, fácil de obtener todo. System Events para un pago dado
-
El marco de datos fundamental para capturar el comportamiento de la aplicación, proporcionando un lugar para construir funcionalidad extensible basada en eventos, que luego puede ser alimentada en tareas de soporte, como proporcionar datos para la supervisión y la alerta.
-
System Event patrón de suscripción de procesadores: "Actúe sobre todas las advertencias de nivel de infraestructura System Events.
-
Configure múltiples procesadores, estilo funcional, almacenar / transformar – emitir a través de un Conector.
-
Todo el System Events que un Servicio IPF puede emitir están catalogados y tienen un esquema, están versionados en relación con el software desplegado.
-
Se recomienda añadir eventos específicos para el cliente para una solución determinada. Proporcionando una extensión muy limpia para aprovechar el marco existente y proporcionar información adicional sobre los datos.
Dónde están definidos
La lista completa de eventos del sistema que produce IPF se encuentra enumerada.aquí.
Resolución de Mensajes de Error
Los eventos en este tabla son eventos de ERROR registrados por IPF y describen los pasos de remediación recomendados a seguir si se encuentran.