Debulker Procesamiento de Clientes
Una instancia de la Debulker puede dividir archivos grandes en componentes impulsados por su configuración (consulte la sección anterior Usando Debulker). Esos componentes pueden ser procesados individualmente a través de aplicaciones o flujos. Esta sección del tutorial demuestra cómo procesar componentes después de que un archivo ha sido desagregado.
| Lo siguiente asume que usted está siguiendo la solución de adición de descomponedor o ha completado la sección anterior.Usando Debulker |
Debulked Procesamiento de Componentes
Cuando un archivo es despojado, sus componentes se añaden al almacén de componentes (actualmente implementado como un MongoDB almacenar-puede ver la colección "componentEntity" si ha completado la sección anterior). Esto significa que esos componentes están disponibles para ser accedidos por aplicaciones externas de la Debulker. Para saber cuándo los componentes están disponibles para el procesamiento, el Debulker se emitirá un Initiate Component Processing Command. Esto puede ser consumido por la aplicación/flujo del cliente e informa al cliente que se ha recibido un lote, se ha desagregado y los componentes están listos para su procesamiento.
El mensaje enviado proporciona el bulkId:
{"bulkId":"pain.001.12345"}Utilizando este bulkId, la aplicación cliente puede consultar la Component Store y utilice la siguiente operación para acceder a los componentes relacionados con ese volumen:
Flow. Publisher<Component<T>> findAllByBulkId(BulkId bulkId);Alternativamente, es posible consultar el almacén de componentes especificando el bulkId y el marcador para el/los componente/s que se desean recuperar. Este es el método que utiliza el Pain001Processor para recuperar el componente raíz que debe ser procesado.
Flux<Component<T>> findAllByBulkIdAndMarkerFlux(BulkId bulkId, String marker);Procesamiento de Componentes de Codificación
Para procesar la notificación Initiate Component Processing Command y acceder a los componentes, nosotros, como mínimo, necesitamos codificar lo siguiente:
-
Conector de Recepción
-
Llamar a Component Store para recuperar componentes
-
Procesamiento para cada componente recuperado
Cada uno de estos puede ser codificado como parte de la aplicación del cliente o un IPF flow. Las opciones para esto dependen de la orquestación que necesite realizar para procesar los componentes, pero es muy probable que el procesamiento de cada componente se realice a través de un IPF flow.
Para los propósitos de este ejemplo, el conector receptor y la llamada al almacén de componentes se implementan en Java solo (dentro de la misma aplicación de debulker) y un IPF flow se inicia para cada componente de nivel de transacción del pain.001 siendo despojado.
| No hay nada que impida el procesamiento del Initiate Component Processing Command y la recuperación de componentes también a través de un IPF Flow, el subyacente Java el código sería en gran medida el mismo. |
Conector de Recepción
La implementación del Conector para este ejemplo de tutorial se puede encontrar en la ipf-debulker-tutorial-app config/connector/DebulkerNotificationConnector.java, este es un Receive Connector<InitiateComponentProcessingCommand> simple. La parte más interesante es el procesamiento de cada notificación recibida, que se implementa en el controlador de recepción en la misma clase:
// ReceiveHandler
private CompletionStage<Void> componentProcessingReceiveConnector(ReceivingContext receivingContext, InitiateComponentProcessingCommand componentProcessingCommand) {
return CompletableFuture.supplyAsync(() -> {
log.info("InitiateComponentProcessingCommand received for bulkId {} ", componentProcessingCommand.getProcessingContext().getClientRequestId().getValue());
Pain001Context pain001Context = Pain001Context.builder()
.marker("Document")
.processingContext(componentProcessingCommand.getProcessingContext())
.build();
componentProcessor.process(componentProcessingCommand.getProcessingContext(), pain001Context); (1)
return null;
});
}| 1 | El procesador de componentes se inyecta a través de Spring Llamar process en el ComponentProcessor pasando el processing Context completo que contiene el bulkId(processingContext.clientRequestId.value). El segundo parámetro, que es un objeto de contexto, puede ser utilizado para pasar parámetros adicionales, por ejemplo, parentId de los procesadores de componentes hijos. |
Configuración
El Receive Connector también necesitará configuración en la aplicación para saber a qué tema acceder. Para el tutorial, esto está configurado para acceder al tema predeterminado para esta notificación (y se colocó en la ipf-debulker-tutorial-app application.conf):
client-processing.connector {
kafka {
consumer {
topic = CLIENT_PROCESSING_REQUEST
}
}
}Procesador de Componentes - Java
Los Procesadores de Componentes deben ser definidos para cada nivel definido en la jerarquía de componentes.
En el ejemplo proporcionado, hay tres niveles definidos en la configuración:
-
Documento
-
CstmrCdtTrfInitn. PmtInf
-
CdtTrfTxInf
El ipf-debulker-starter el módulo incluye un ComponentProcessor, para definir un procesador específico, simplemente extienda esta clase.
Procesador de Componentes de Documentos
public class Pain001Processor extends ComponentProcessor<Document, Pain001Context> { (1)
private final Pain001PaymentInstructionProcessor nextProcessor;
public Pain001Processor(ComponentStore<NoCustomData> componentStore, Pain001PaymentInstructionProcessor nextProcessor) {
super(componentStore, Pain001Processor::map, true); (2)
this.nextProcessor = nextProcessor;
}
// Used to unmarshall the XML to an iso20022 model object
private static Document map(String xmlString) {
String PAIN_001_NAMESPACE = "urn:iso:std:iso:20022:tech:xsd:pain.001.001.09";
XMLMapper xmlMapper = new XMLMapper();
xmlMapper.registerDocumentClass(PAIN_001_NAMESPACE, Document.class);
return xmlMapper.fromXML(xmlString, Document.class);
}
@Override
protected Class<Document> getTargetClass() {
return Document.class;
}
@Override
protected CompletionStage<Done> handle(Pain001Context result) { (3)
Document unmarshalledComponent = xmlMapper.apply(result.rawContent()); (4)
Pain001PaymentInstructionContext pain001PaymentInstructionContext = Pain001PaymentInstructionContext.builder()
.parentId(result.componentId())
.processingContext(result.processingContext().withUnitOfWorkId(UnitOfWorkId.createRandom()))
.parentMarker(result.marker())
.build();
return nextProcessor.process(result.processingContext(), pain001PaymentInstructionContext) (5)
.thenApply(__ -> new Done("", "", "", Done. Result. EXECUTED)); (6)
}
@Override
protected Function<Pain001Context, ComponentId> getParentComponentId() { (7)
return null;
}
@Override
public Function<Pain001Context, String> getMarker() { (8)
return Pain001Context::marker;
}
@Override
protected Function<Component<NoCustomData>, Pain001Context> transformComponent(Pain001Context additionalData) { (9)
return component -> additionalData.toBuilder()
.componentId(component.getId())
.marker(component.getMarker())
.rawContent(component.getContent())
.build();
}
}NOTA: Un componente raíz es aquel que no tiene un padre.
| 1 | El primer parámetro de tipo es el tipo asociado al contenido deserializado del componente y el segundo tipo es el tipo asociado al contexto del componente. El contexto del componente se define como una clase de registro separada.Pain001Context en este caso y facilita el paso de datos de contexto adicionales con el componente recuperado de la tienda de componentes. Los datos definidos en el registro variarán dependiendo de qué datos se necesiten pasar con el componente. |
| 2 | El tercer parámetro del constructor indica que este es un procesador de componentes raíz. Esto afecta la consulta utilizada para recuperar los componentes del almacén de componentes. Tenga en cuenta que se espera que los procesadores de componentes raíz solo devuelvan un único componente. |
| 3 | El handle El método se llama para cada componente que se recupera del almacén de componentes y especifica el procesamiento que debe ocurrir en cada componente. En este caso, estamos llamando al siguiente nivel de procesamiento (instrucción de pago). |
| 4 | Aunque no se utiliza en este ejemplo, es posible deserializar el contenido en bruto recuperado del almacén de componentes, lo cual podría ser útil si existe la necesidad de recuperar datos del contenido en bruto. |
| 5 | El siguiente procesador se llama directamente aquí, pero esto también podría hacerse a través de un MPS flujo |
| 6 | Dado que no estamos llamando a un MPS flujo, estamos creando un "dummy" Done objeto, ya que esto normalmente sería devuelto por una invocación de un flujo |
| 7 | Dado que este es un procesador de componentes raíz, no hay parentId. |
| 8 | El marcador se utiliza además del bulkId para recuperar el componente raíz del almacén de componentes. |
| 9 | Este método permite enriquecer los datos recuperados del almacén de componentes con información adicional. |
Instrucción de Pago (PmtInf) Componente Procesador
public class Pain001PaymentInstructionProcessor extends ComponentProcessor<PaymentInstruction30, Pain001PaymentInstructionContext> { (1)
private final Pain001TransactionProcessor nextProcessor;
public Pain001PaymentInstructionProcessor(ComponentStore<NoCustomData> componentStore, Pain001TransactionProcessor nextProcessor) {
super(componentStore, Pain001PaymentInstructionProcessor::map, false); (2)
this.nextProcessor = nextProcessor;
}
// Used to unmarshall the XML to an iso20022 model object
private static PaymentInstruction30 map(String xmlString) {
String PAIN_001_NAMESPACE = "urn:iso:std:iso:20022:tech:xsd:pain.001.001.09";
XMLMapper xmlMapper = new XMLMapper();
xmlMapper.registerDocumentClass(PAIN_001_NAMESPACE, PaymentInstruction30.class);
return xmlMapper.fromXML(xmlString, PaymentInstruction30.class);
}
@Override
protected Class<PaymentInstruction30> getTargetClass() {
return PaymentInstruction30.class;
}
@Override
protected CompletionStage<Done> handle(Pain001PaymentInstructionContext result) {
PaymentInstruction30 unmarshalledComponent = xmlMapper.apply(result.rawContent());
Pain001TransactionContext pain001TransactionContext = Pain001TransactionContext.builder()
.parentId(result.componentId())
.parentMarker(result.marker()) (3)
.processingContext(result.processingContext().withUnitOfWorkId(UnitOfWorkId.createRandom()))
.build();
// We are calling the next level processor directly, but you could do this via an MPS flow also
return nextProcessor.process(result.processingContext(), pain001TransactionContext)
.thenApply(__ -> new Done("", "", "", Done. Result. EXECUTED));
}
@Override
protected Function<Pain001PaymentInstructionContext, ComponentId> getParentComponentId() { (4)
return Pain001PaymentInstructionContext::parentId;
}
@Override
public Function<Pain001PaymentInstructionContext, String> getMarker() {
return pain001TxContext -> pain001TxContext.parentMarker() + ". CstmrCdtTrfInitn. PmtInf"; (5)
}
@Override
protected Function<Component<NoCustomData>, Pain001PaymentInstructionContext> transformComponent(Pain001PaymentInstructionContext additionalData) {
return component -> additionalData.toBuilder()
.componentId(component.getId())
.marker(component.getMarker())
.rawContent(component.getContent())
.build();
}
}| 1 | Al igual que con el Pain001Processor, se requieren argumentos de tipo genérico aquí. En este caso, el tipo deserializado es un PaymentTransaction39 y un nuevo Pain001PaymentInstructionContext el tipo de registro se define para transmitir el componente de instrucción de pago con datos adicionales. |
| 2 | Dado que los componentes de instrucciones de pago tienen un padre, el rootComponentProcessor el indicador está configurado a false |
| 3 | Creación de un nuevo objeto de contexto aquí, que se utilizará para el siguiente nivel de procesamiento (procesamiento a nivel de transacción). Estableciendo el parentMarker desde el contexto actual. |
| 4 | Pasó de punto 3 esto se utiliza en la consulta para recuperar los componentes relevantes del almacén de componentes |
| 5 | Construyendo dinámicamente el marcador basado en el marcador padre y el sufijo que identifica el nivel actual del componente. |
Componente Procesador de Transacción (CdtTrfTxInf)
public class Pain001TransactionProcessor extends ComponentProcessor<CreditTransferTransaction39, Pain001TransactionContext> { (1)
public Pain001TransactionProcessor(ComponentStore<NoCustomData> componentStore) {
super(componentStore, Pain001TransactionProcessor::map, false); (2)
}
// Used to unmarshall the XML to an iso20022 model object
private static CreditTransferTransaction39 map(String xmlString) {
String PAIN_001_NAMESPACE = "urn:iso:std:iso:20022:tech:xsd:pain.001.001.09";
XMLMapper xmlMapper = new XMLMapper();
xmlMapper.registerDocumentClass(PAIN_001_NAMESPACE, CreditTransferTransaction39.class);
return xmlMapper.fromXML(xmlString, CreditTransferTransaction39.class);
}
@Override
protected Class<CreditTransferTransaction39> getTargetClass() {
return CreditTransferTransaction39.class;
}
@Override
protected CompletionStage<Done> handle(Pain001TransactionContext result) { (3)
CreditTransferTransaction39 cdtTrfTxInf = xmlMapper.apply(result.rawContent());
String unitOfWorkId = UUID.randomUUID().toString(); // UOW Id to uniquely identify a request.
String clientRequestId = cdtTrfTxInf.getPmtId().getEndToEndId(); // Payment related Id
log.info("cdtTrfTxInf is instance of CreditTransferTransaction-initiate flow to process, UOW Id {}", unitOfWorkId);
return DebulkerModelDomain.initiation().handle(new InitiateProcessDebulkedComponentsInput. Builder() (4)
.withProcessingContext(ProcessingContext.builder()
.unitOfWorkId(unitOfWorkId)
.clientRequestId(clientRequestId)
.build())
.withIsoCreditTransferComponent(cdtTrfTxInf)
.withPaymentJourneyType("PAYMENT")
.build()
).thenApply(report -> {
log.debug("{}: Transaction Validation outcome is {}", cdtTrfTxInf.getPmtId().getEndToEndId(), report.getResult());
return report;
});
}
@Override
protected Function<Pain001TransactionContext, ComponentId> getParentComponentId() {
return Pain001TransactionContext::parentId;
}
@Override
public Function<Pain001TransactionContext, String> getMarker() {
return pain001TransactionContext -> pain001TransactionContext.parentMarker() + ". CdtTrfTxInf";
}
@Override
protected Function<Component<NoCustomData>, Pain001TransactionContext> transformComponent(Pain001TransactionContext additionalData) {
return component -> additionalData.toBuilder()
.componentId(component.getId())
.marker(component.getMarker())
.rawContent(component.getContent())
.build();
}
}<1>`Pain001TransactionContext` sirve como un mecanismo para transmitir datos del nivel de procesamiento anterior, por ejemplo,parentMarker
<2> Dado que las transacciones tienen un padre, este no es un procesador de componentes raíz.
<3> En este caso, el procesamiento de cada componente recuperado implica invocar un ProcessDebulkedComponents MPS flujo
<4> MPS el flujo se inicia aquí, utilizando el contenido del componente de transacción desmarshalled recuperado de la tienda de componentes
Flujo de Procesamiento de Componentes - ProcessarComponentesDespojados
No entraremos en gran detalle sobre este flujo, ya que está creado para proporcionar un ejemplo funcional y demostrar cómo pasamos de los componentes debulker a la Component Store, para iniciar flujos para procesar cada componente.
La razón principal para crear este flujo es establecer el vínculo entre el tipo de Componente y realizar algún tipo de procesamiento dentro de un IPF flow. Lo que ese procesamiento subsecuente sea depende de su caso de uso, pero este ejemplo ahora es capaz de procesar un Customer Credit Transfer del archivo despojado.
Echemos un vistazo rápido a las partes importantes del ejemplo de flujo para unir los puntos.

Este tipo de datos ('On Received Data') envuelve esencialmente el Credit Transfer Transaction39 y ha sido implementado como un Business Data Biblioteca (no era necesario hacer esto, se podría haber utilizado el Credit Transfer Transaction39 directamente, pero esto le muestra que puede definir su propio tipo alineado con el componente que está procesando).

El resto del procesamiento del flujo es en gran medida académico, pero se añade un paso de validación para acceder realmente a los datos; esta es la función del dominio:
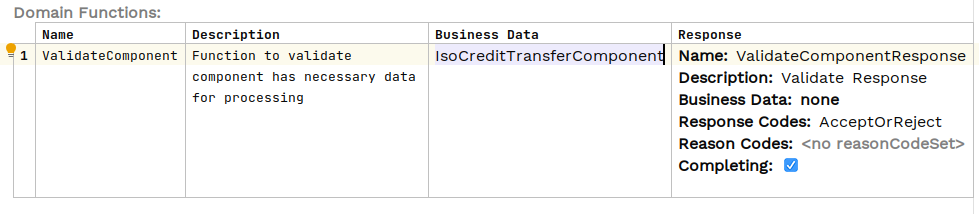
El Java La implementación de la validación simplemente accede a los objetos de Transferencia de Crédito EndToEndId y registra esto:
public class DebulkerComponentsFunctionsAdapter implements DebulkerComponentsFunctionsPort {
@Override
public CompletionStage<ValidateComponentResponseInput> execute(ValidateComponentAction validateComponent) {
if (validateComponent.getIsoCreditTransferComponent().getPmtId().getEndToEndId()!= null ) {
// accept if E2E ID populated (crude but does something with the data supplied to prove processing for now)
log.info("Component is valid - E2E ID is populated {} for Event ID {} & UOW Id {}",
validateComponent.getIsoCreditTransferComponent().getPmtId().getEndToEndId(),
validateComponent.getId(),
validateComponent.getProcessingContext().getUnitOfWorkId());
return CompletableFuture.completedStage(new ValidateComponentResponseInput. Builder(validateComponent.getId(), AcceptOrRejectCodes. Accepted).build());La aplicación ipf-debulker-tutorial-app requiere MongoDB, Kafka y el DebulkerModelDomain haber sido configurado (consulte la clase app/config/ProcessDebulkedConfig). Ninguno de estos aspectos se cubre en detalle aquí, pero el código se puede encontrar en la solución add_debulker y los detalles sobre los principios para esos pasos se abordan en módulos de tutorial anteriores (consulte DSL 3 - Uso de una Función de Dominio, DSL 12 - Usando custom datos empresariales, &CON2 - Escribiendo su propio conector (Kafka)).
Ejecutando la aplicación
Puede iniciar application.yml utilizando el siguiente comando:
docker-compose -f application.yml up -dProbando la aplicación
Ahora que la aplicación está iniciada, podemos probarla (de manera similar a la sección anterior.Usando Debulker, esto se realiza por:
-
Proporcionando un archivo de datos fuente en la ubicación esperada (utilizaremos un archivo más completo esta vez).
-
Enviando una Notificación de Archivo al ipf-debulk, a través de Kafka, para notificar a la aplicación que un archivo está listo para ser procesado.
-
Validando que el archivo esté despojado, verificando el Component Store.
-
Validando que los componentes han sido recuperados de la Component Store, por nuestra aplicación.
-
Validando que los componentes han sido procesados a través del nuevo IPF flow ProcessarComponentesDespojados.
Paso 1 - Creación de pain.001 archivo que será despojado
Para esta prueba, utilizaremos una versión más completa del PAIN. 001 e incluiremos algunos atributos adicionales dentro del componente de Transferencia de Crédito.
Se incluye un archivo de ejemplo.-pain_001_test_full.xml
Este archivo ya está creado y se encuentra en el directorio solutions/add-debulker/docker/bulk_files/.
Paso 2 - Enviando FileNotification a Kafka
Hemos configurado la aplicación para recibir FileNotifications de Kafka, esa notificación tiene varias propiedades que deben ser proporcionadas:
-
configName-nombre de la configuración que será utilizada por el debulker para descomponer el archivo en componentes.
-
bulkId-para correlacionar los componentes producidos por el desmenuzador.
-
fileProvider-nombre del proveedor que se utilizará para recuperar el archivo masivo para su procesamiento.
-
filePath-ruta al archivo.
Mensaje de notificación de archivo a enviar:
{
"configName": "pain.001.001.09",
"bulkId": "pain.001.99999",
"fileProvider": "local",
"filePath": "/tmp/bulk_files",
"fileName": "pain_001_test_full.xml"
}podemos enviar el archivoNotification a Kafka usando Productor de consola Kafka:
./kafka-console-producer.sh --topic FILE_NOTIFICATION_REQUEST --bootstrap-server localhost:9092O utilizando la interfaz de usuario de kafka proporcionada:http://localhost:8098/ui/clusters/local/all-topics/FILE_NOTIFICATION_REQUEST

Seleccione Producir Mensaje, especificando lo siguiente como el valor, la clave puede dejarse en blanco.
El mensaje que estamos enviando debe estar en una sola línea:
{"configName": "pain.001.001.09", "bulkId": "pain.001.99999", "fileProvider": "local", "filePath": "/tmp/bulk_files/", "fileName": "pain_001_test_full.xml"}
Paso 3 Validando que el archivo esté descomprimido
En este punto, el desagregador debe haber recibido la notificación, accedido al archivo y desagregado el mismo. Para este tutorial y prueba, lo más importante que nos interesa validar es que los componentes deben estar presentes en el Component Store.
Esto se puede verificar fácilmente a través del almacén de componentes. REST API(según el tutorial anterior para el deshidratador-Validar Archivo Debulk).
Ejecute esto desde la línea de comandos para obtener todos los componentes relacionados con nuestra compra masiva:
curl http://localhost:8080/v1/components/pain.001.99999 | json_ppEste debería ser el resultado esperado para el archivo pain_001_test_full.xml desglosado. Críticamente, debe haber dos componentes con el siguiente marker, representando el Customer Credit Transfer:
"marker": "Document. CstmrCdtTrfInitn. PmtInf. CdtTrfTxInf",Y teniendo content que comienza:
"content": "<CdtTrfTxInf><PmtId><InstrId>..Paso 4 Validación de la Recuperación de Componentes y la Iniciación del Flujo
En este punto, también debería haberse enviado un InitiateComponentProcessingCommand a Kafka, y esto debería haber sido detectado por nuestra aplicación. Específicamente, debería haber sido a través de la receiveHandler implementamos. En el momento de redactar, podemos ver esto en los registros de la aplicación ipf-tutorial-debulking-app:
2023-06-06 06:20:38.767 INFO c.i.i.t.d.a.c.c. DebulkerNotificationConnector - InitiateComponentProcessingCommand received for bulkId pain.001.99999En el ComponentProcessor se registra la iniciación del flujo:
2023-06-06 06:20:39.147 INFO c.i.i.t.d.a.c. Pain001TransactionProcessor-cdtTrfTxInf is instance of CreditTransferTransaction-initiate flow to process, UOW Id 938ece8d-bca8-47af-8f69-068b140319c3Paso 5 Validar ProcesoComponentes Despojados Flujo de procesamiento
Puede validar el procesamiento del componente utilizando IPF Developer App on localhost:8081
Al hacer clic Get Transactions debería haber dos registros asociados a los dos componentes de nivel de transacción que tienen triggered ProcessDebulkedComponents flujo.
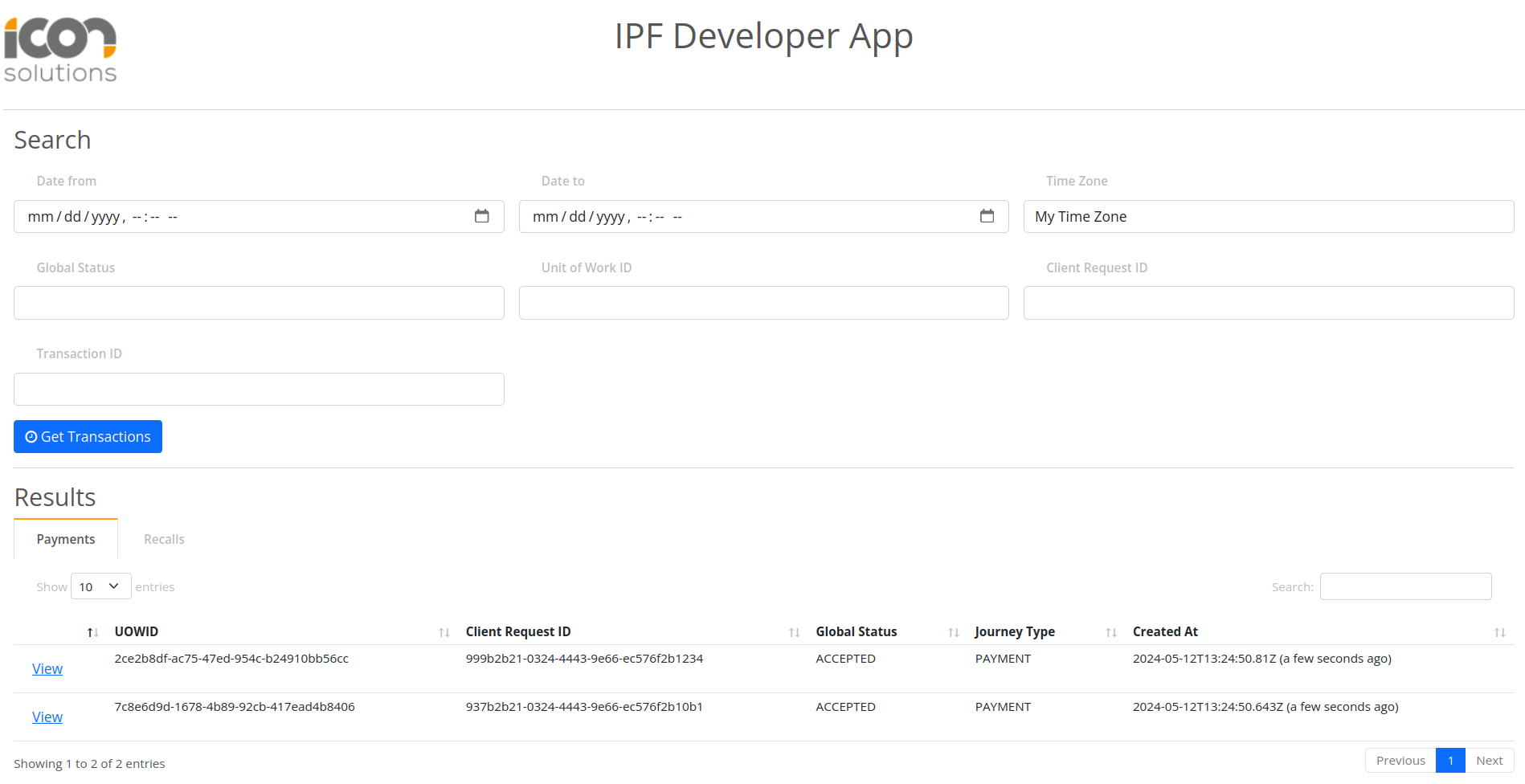
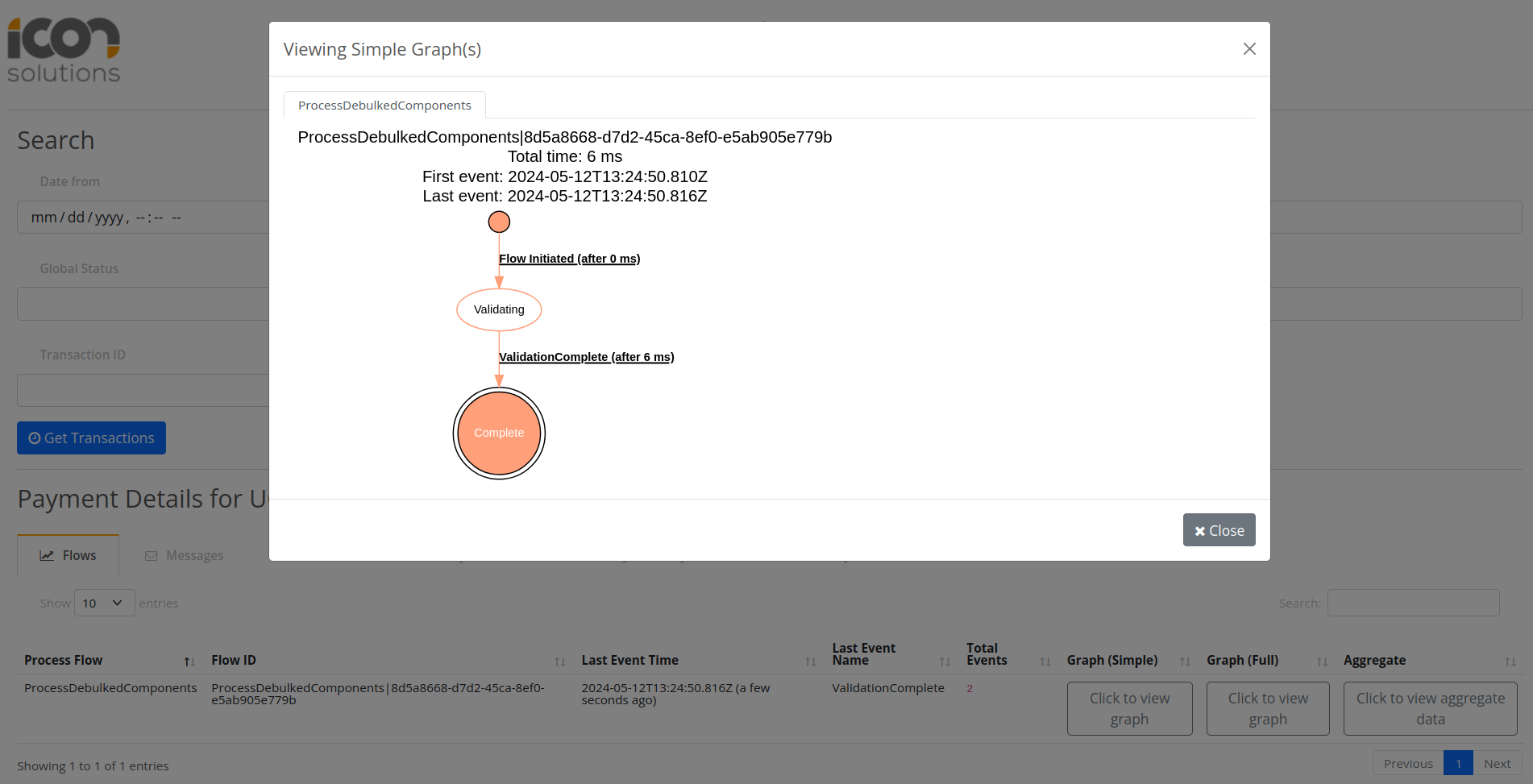
Conclusiones
En esta sección nosotros:
-
Se muestra cómo procesar Debulked Componentes mediante el procesamiento del InitiateComponentProcessingCommand enviado por el Debulker al completar.
-
Código implementado para acceder al Component Store y recupere todos los componentes.
-
Para cada componente relevante iniciado un IPF flow.
-
Procesó esos componentes a través de un IPF flow.