Resiliencia de Aplicaciones a través de Akka Cluster Sharding
Introducción
Este documento existe para comunicar cómo IPF applications usar Akka Cluster Sharding para la recuperación y la resiliencia. Esto no es un análisis profundo en Akka Cluster Se proporcionan fragmentos y referencias para una lectura adicional. Lo clave a tener en cuenta al revisar y comprender cómo IPF proporciona resiliencia y recuperación, es que IPF hace uso de la Akka características y un IPF flow es meramente una entidad dentro de un sistema Actor.
Akka Cluster Sharding
Akka ClusterSharding funciona permitiendo que una aplicación se escale a través de múltiples nodos (instancias de aplicación), distribuyendo entidades (flujos en IPF) entre varios nodos en un clúster, enviando mensajes a ellos a través de un ID único, pero sin tener que preocuparse en qué nodo reside la entidad en el clúster. Este último punto es crucial para cómo Akka proporciona resiliencia y puede mover transparentemente la ubicación de una entidad a otro nodo en caso de fallo.
Definiciones
Entidad-para nuestra discusión, una entidad es el equivalente a una instancia de un IPF Flow(i.e. la instancia de un IPF flow procesando una transacción única particular).
Fragmento - Un shard es un grupo de entidades que serán gestionadas juntas.
Región de Shard - Actúa como mediador para los fragmentos y gestiona el enrutamiento de mensajes a la entidad correcta, ya sea a uno de sus fragmentos o a través de otra región de fragmentos en otros nodos.
Nodo - Entorno de ejecución para su IPF application(normalmente un pod dentro de un entorno en contenedores).
Persistencia-el almacenamiento del estado de las entidades mediante el registro de todos sus eventos.
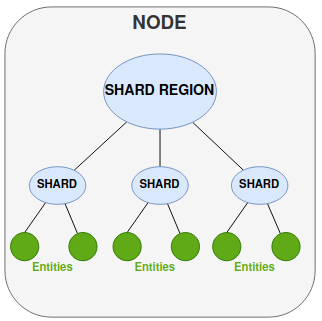
Puntos Clave
-
El sharding significa que los actores con un identificador, llamado entidades, pueden ser distribuidos automáticamente a través de múltiples nodos en el clúster.
-
Cada actor de entidad (IPF flow la instancia) se ejecuta solo en un lugar.
-
Los mensajes que deben ser procesados por una entidad pueden ser enviados a la entidad (IPF flow instancia) sin requerir que el remitente conozca la ubicación física del actor de destino.
-
La ubicación física de la entidad puede cambiar con el tiempo.
-
La persistencia se utiliza junto con el Cluster Sharding para recuperar el estado de una entidad (IPF Flow) después de que se haya movido.
-
Desde Akka La persistencia se basa en un principio de un solo escritor; solo un actor persistente está activo en cualquier lugar dentro del clúster.
-
El uso compartido de clústeres también ayuda con la escalabilidad para permitir la distribución de muchos actores con estado en más de una unidad de procesamiento (típicamente un pod).
| Los siguientes escenarios hablan mucho sobre cómo Akka el agrupamiento está funcionando en IPF porque su funcionalidad principal subraya cómo se gestionan los flujos. Donde lea la palabra "entidad", intercámbiela por " IPF flow instancia". |
Operación del Clúster BAU
Considere un despliegue típico de su aplicación de procesamiento de pagos IPF (una aplicación Springboot que envuelve el IPF flow/ s, ejecute dentro de un pod). En este ejemplo tenemos 3 nodos (3 instancias del pod).
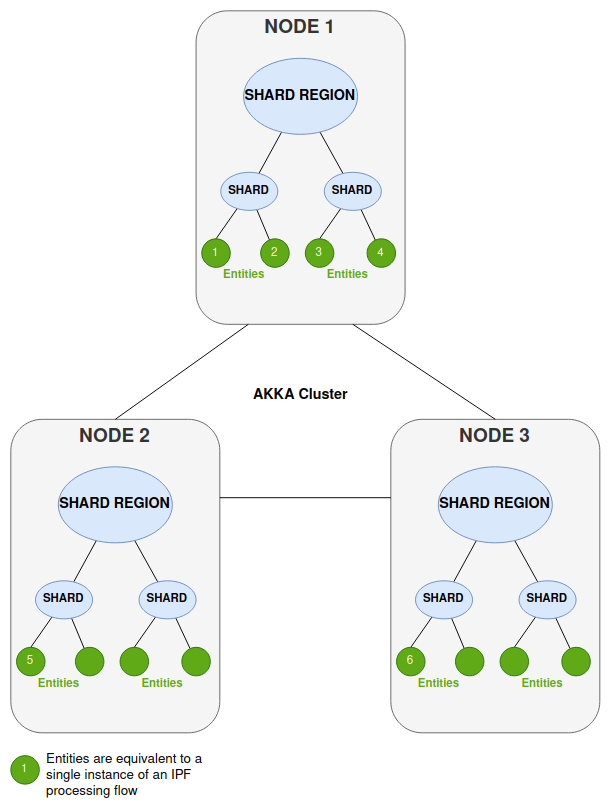
Solo una instancia de una entidad se ejecuta en el clúster en un momento dado, pero los mensajes entrantes pueden llegar a diferentes nodos.
Así que, por ejemplo, cuando un mensaje llega a una Región de Shard pero la ubicación de esa entidad se encuentra en otra región en un nodo separado, el mensaje se enruta dentro de la Akka Cluster al fragmento correcto para ser procesado por la entidad única (IPF flow instancia). En el diagrama a continuación, las siguientes cosas están sucediendo cuando se procesa un mensaje en un nodo específico.
-
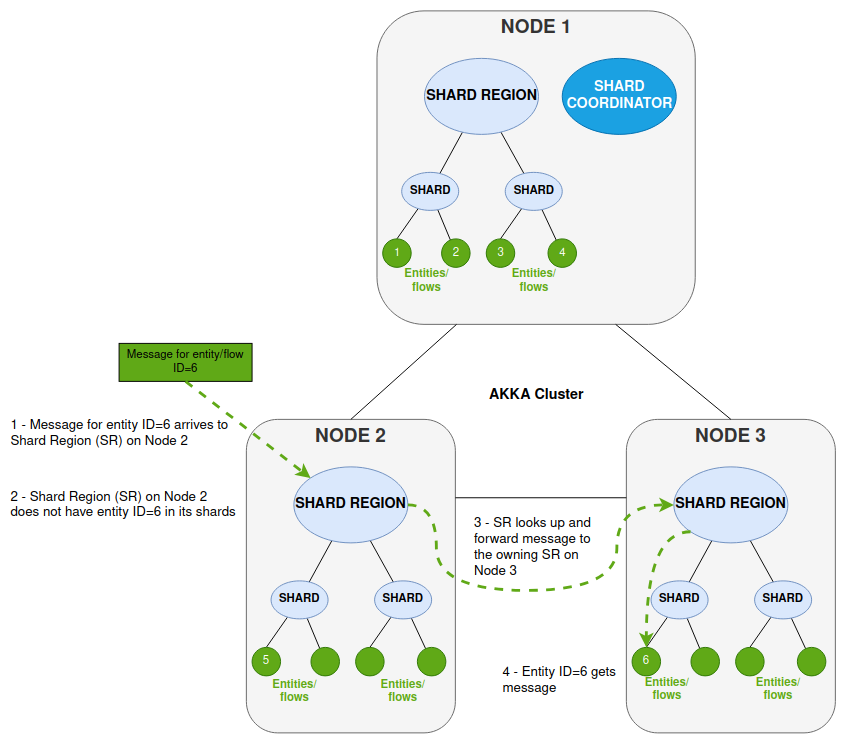
El nodo 2 recibe el mensaje que es para la entidad/flujo ID=6.
-
La Región Shard (SR) en el Nodo 2 no tiene esa entidad dentro de ninguno de sus shards (la entidad ID=6 no está en funcionamiento en el Nodo 2).
-
SR en el Nodo 2 busca la ubicación de la entidad y reenvía el mensaje a través del Akka Cluster al SR que se ejecuta en el Nodo 3
-
El SR en el Nodo 3 conoce la ID de entidad=6 y reenvía el mensaje para su procesamiento por esa entidad.
El escenario real para esto desde una perspectiva de procesamiento de IPF es donde usted tiene múltiples nodos procesando desde el mismo Kafka temas.
-
Donde el IPF flow envía una solicitud a un dominio externo, el nodo que procesa la respuesta no está controlado en el Kafka nivel.
-
Cada nodo leerá las respuestas del mismo Kafka el tema, pero el nodo que lee la respuesta podría no haber sido el nodo que procesó la solicitud (y, por lo tanto, la ubicación de la entidad de flujo)
Esto es la Transparencia de Ubicación, y significa que para el procesamiento de BAU el clúster maneja el enrutamiento a una ubicación física, y podemos referirnos a la entidad simplemente por su ID lógico. Así es como IPF funciona para enrutear los mensajes a la correcta IPF flow instancia. Y esto es crucial no solo desde una perspectiva de BAU, sino también desde una perspectiva de resiliencia y escenarios de fallo, para hacer frente a la falla de nodos y reiniciar.
Tenga en cuenta la introducción de un Coordinador de Shard. Este tiene una serie de responsabilidades y es crucial para permitir la transparencia de enrutamiento y ubicación. Los shards son gestionados por el Coordinador de Shard (SC) y este:
-
es un clúster singleton(solo hay 1 dentro de un Akka Cluster)
-
monitorea los nodos del sistema y la ubicación de cada fragmento
-
asegura que el sistema sepa dónde enviar mensajes para una entidad específica
-
decide qué fragmento reside en qué región de fragmentos
-
Está respaldado por Akka persistencia – para reproducir eventos en caso de fallo del SC para permitirle reanudar su estado.
Escenario de Nodo Caído
Lo siguiente muestra lo que sucede en el Akka Cluster cuando un nodo falla o se reinicia. La funcionalidad y el comportamiento aquí aseguran que las entidades puedan reanudarse en otros nodos y que el procesamiento pueda continuar con normalidad independientemente de la falla del nodo.
En este escenario, están ocurriendo dos cosas donde alguna infraestructura está caída, lo que hace que una Región de Fragmento (SR) no esté disponible.
-
El nodo 2 recibe el mensaje que es para la entidad/flujo ID=6.
-
La Región Shard (SR) en el Nodo 2 no tiene esa entidad dentro de ninguno de sus shards (la entidad ID=6 no está en funcionamiento en el Nodo 2).
-
El SR que recibe el mensaje intenta enviarlo al SR que tiene la entidad (esto fue en el Nodo 3)
-
Pero el SR en el Nodo 3 ya no está disponible.
-
El Coordinador de Shard interviene para mover el Shard a un SR diferente (en nuestro caso, el Nodo 1).
-
SR en el Nodo 2 ahora reenvía el mensaje a través del Akka Cluster al SR que se ejecuta en el Nodo 1
-
El SR en el Nodo 1 conoce la ID de entidad=6 (su Shard fue trasladado aquí) y reenvía el mensaje para su procesamiento por esa entidad.
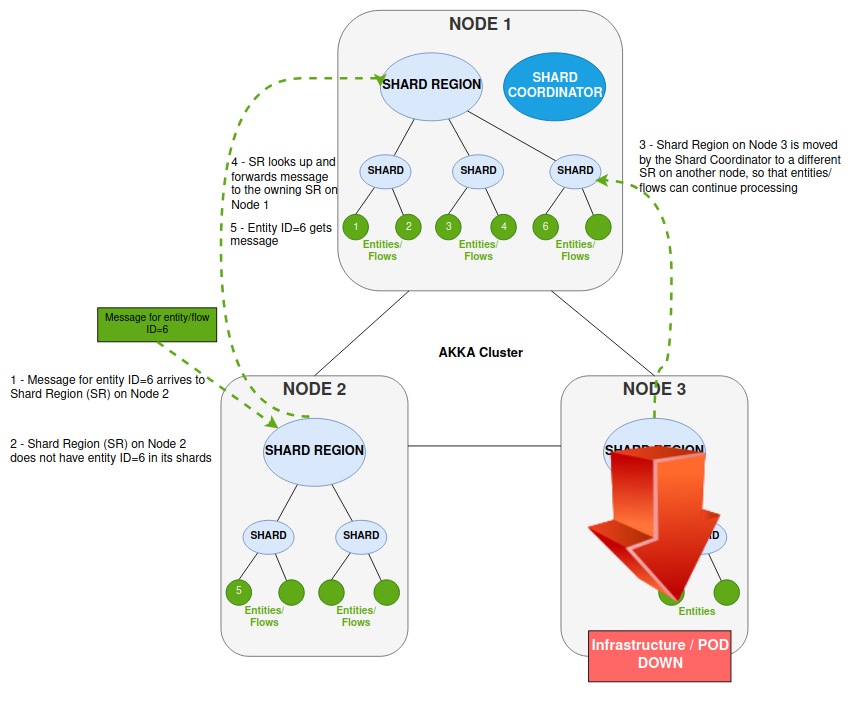
Las cosas más importantes a tener en cuenta en este escenario son que la ubicación del flujo en ejecución (entidad) es transparente, y es el Akka Cluster que proporciona el enrutamiento al fragmento correcto y, por ende, al nodo. Cada entidad se ejecuta en un solo lugar y, por lo tanto, aquellas entidades en ejecución pueden ser distribuidas y movidas por el clúster sin que ningún remitente tenga que conocer la ubicación/nodo del actor de destino. Las entidades son persistentes y, por lo tanto, pueden reanudarse en cualquier fragmento en cualquier nodo, ya que se reproducirán los eventos para reanudar el estado correcto.
Particiones de Red / Resolución de Cerebro Dividido
Por defecto, implementamos el método predeterminado de resolución de división de cerebro de mantener la mayoría en IPF proporcionado por Akka, esto permite la mejor combinación de escalabilidad en un entorno de nube.
| Estrategia | Requisitos |
|---|---|
mantener-mayoría (predeterminado) |
Número impar de nodos en total Akka Cluster |
lease-majority |
Debe ser un único Kubernetes clúster |
keep-oldest |
Podría llevar a la terminación del quórum más grande. |
Si un cliente está operando en un entorno donde solo están disponibles dos Centros de Datos, y cada centro de datos tiene su propia aislada Kubernetes cluster, luego keep-oldest se ocupa de escenarios en los que un único DC (la mitad de los nodos) se encuentra particionado y utiliza el cluster singleton actuar en arbitraje para la salud del clúster.
Preguntas Comunes
P. ¿Cómo sabe la Región de Fragmentos (SR) qué entidades/instancias de flujo tiene?
El SR realiza un seguimiento de todos los shards y entidades que tiene. Esto significa que no necesita resolver la ubicación externamente (con el Coordinador de Shards) cada vez.
P. Si el fragmento se encuentra en otro SR, ¿cómo se envía el mensaje al SR correcto (y, por ende, al nodo)?
Si el fragmento se encuentra en otro SR, entonces los mensajes deben ser reenviados a ese SR en su lugar. El SR que recibe el mensaje debe resolver la ubicación del fragmento objetivo desde el clúster, y el Coordinador de Fragmentos (SC) es responsable de conocer la ubicación de todos los fragmentos y entidades en todo el clúster. Una vez que se resuelve la ubicación, los mensajes se entregan al fragmento objetivo.
P. Mientras el SR está resolviendo la ubicación de un fragmento, ¿qué sucede con los mensajes entrantes para esa entidad?
Mientras se resuelve la ubicación del fragmento, los mensajes entrantes se almacenan en un búfer y se entregarán más tarde una vez que se conozca la ubicación del fragmento. Cualquier mensaje subsiguiente que se resuelva a ese fragmento 'remoto' puede ser entregado a la destino objetivo de inmediato sin involucrar al coordinador del fragmento para determinar la ubicación.
P. ¿Cómo aseguramos que no se pierda ningún estado al mover entidades/flujos entre SR?
Utilizamos Akka persistencia para almacenar los eventos y permitir que el estado de un actor sea recuperado al reproducir eventos en el reinicio de la entidad/flujo.
| el coordinador de fragmentos también está respaldado por Akka persistencia – para reproducir eventos en caso de fallo y permitir que reanude su estado. |
Q. Si un nodo envía una solicitud a un dominio externo (por ejemplo, Sanciones) pero su respuesta se lee desde Kafka por un nodo diferente, ¿cómo obtiene el flujo correcto esa respuesta?
Este es el escenario descrito anteriormente en "Operación del Clúster BAU" y es la operación normal, ya que deseamos la Transparencia de Ubicación para la entidad (lo que significa que puede ser trasladada o recuperada según sea necesario).
P. Si un nodo falla, ¿qué sucede con las entidades/flujos que se procesan en la región de fragmento de ese nodo?
Este es el escenario descrito anteriormente en "Escenario de nodo caído" y abarca cómo se mueven los fragmentos con sus entidades para ejecutarse dentro de otra región de fragmentos.
P. ¿Qué es el reequilibrio de fragmentos?
Este es el proceso mediante el cual el coordinador de fragmentos facilita el reequilibrio de fragmentos, donde se añaden nuevos miembros al clúster. Así, las entidades pueden ser trasladadas de un nodo a otro. El proceso de reequilibrio hará que las regiones de fragmentos almacenen mensajes entrantes para un fragmento y el coordinador no responderá a las solicitudes de ubicación hasta que el reequilibrio se complete. Por lo tanto, esos mensajes de entidad se almacenan hasta que el coordinador responda a las solicitudes de ubicación, momento en el cual se puede reanudar el enrutamiento de esos mensajes almacenados.
P. ¿Qué sucede si el coordinador de fragmentos falla?
El estado del coordinador de fragmentos es persistente y, por lo tanto, puede ser recuperado. Si el coordinador falla o el nodo se vuelve inalcanzable, se debe establecer un nuevo coordinador de fragmentos.singleton tomará el control y el estado se recupera del almacenamiento persistente. Durante este tiempo, cualquier ubicación conocida sigue estando disponible para las regiones de fragmentos, pero cualquier solicitud de ubicaciones se almacena en búfer hasta que el coordinador vuelva a estar en línea.
Referencia
Para más información sobre los conceptos de compartición de clústeres, consulte aquí.
Para una inmersión más completa en los detalles técnicos de Akka Cluster Por favor, lea sobre el sharding.https://doc.akka.io/docs/akka/current/typed/cluster-sharding.html[aquí].
Para un análisis técnico sobre cómo Akka Cluster ing funciona (con ejemplos de código) esto vale la pena verlo, parte 1 aquí.
Para obtener detalles sobre la Resolución de Cerebro Dividido, consulte aquí.