Servicio de Ingesta
ODSconsume IPF Processing Data from Kafka, lo transforma en el ODS modelo de datos y persiste en la base de datos.
Los datos relacionados con un pago llegan con un contexto de procesamiento compuesto por
-
unitOfWorkId- agrupa todos los datos para un único pago/unidad de trabajo -
associationId- identifica el flujo del cual se originó los datos -
clientRequestId- el identificador de solicitud original del cliente para el pago/unidad de trabajo -
processingEntity- agrupa los pagos bajo diferentes entidades
El flujo general de alto nivel para el procesamiento de datos de IPF a persistidos. ODS data es:
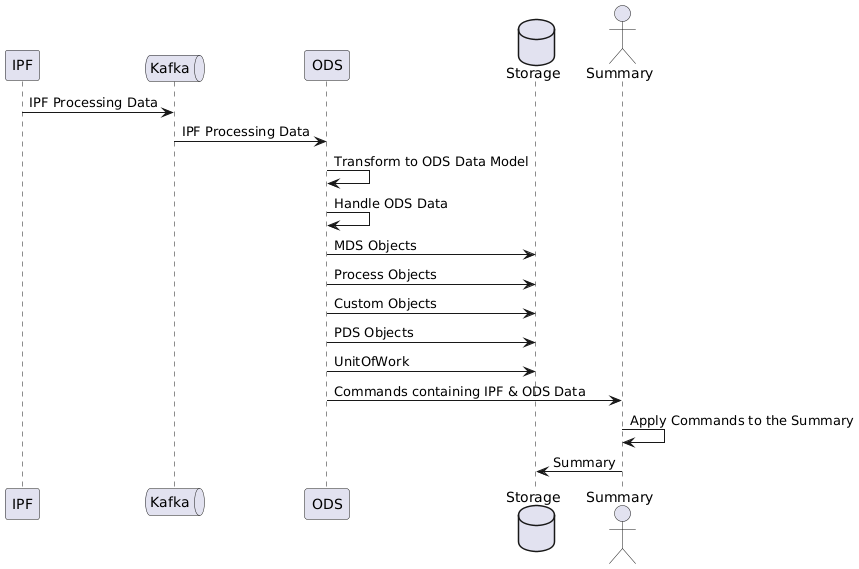
UnitOfWork
Una sola UnitOfWork se persiste en la base de datos para cada unitOfWorkId que es procesado por IPF, esto sirve como meta-datos para un dado unitOfWork.
Process Flow Eventlas marcas de tiempo se persisten en el UnitOfWork objetos, y se utilizan para identificar el inicio y el final de un unitOfWork ciclo de vida.
Resumen
Algunos de los persistidos ODS Los datos se publican a un actor de resumen de pagos, que aplica los datos a su vez para crear/actualizar una vista de resumen persistente.
Los datos se mapean en campos de resumen, como se describe en el Resumen de Mapeo página.
Soportado Data Type s
Los tipos de datos admitidos para los datos que pertenecen a un pago se dividen en cuatro categorías: mds, pds, proceso y custom.
MDS Objetos
MDSLos objetos son aquellos que se originan a partir de objetos ISO 20022.- por ejemplo un pain.001 La instrucción contiene un encabezado de grupo, una o más instrucciones, y dentro de cada instrucción, una o más transacciones de transferencia de crédito. Cada uno se considera un distinto MDS objeto, que pertenece al pago original o unidad de trabajo. Cuando un pain.001 es recibido por un flujo de procesamiento IPF, se descompone en partes, y todas esas partes se publican en ODS en un solo mensaje.
PDS Objetos
PDSlos objetos son tipos definidos por IPF, por ejemplo, Csm, o JourneyType, o son definidos por el cliente custom tipos. Una unidad de trabajo puede tener solo un único PDS objeto por nombre, y rastrea diferentes versiones de ese objeto con un número de secuencia.
El mayor número de secuencia de todas las versiones de un específico PDS el objeto se considera la versión "más reciente" de ese objeto.
Duplicar PDS Los objetos, donde el nombre y el número de secuencia son los mismos para una unidad de trabajo dada, son ignorados.
Process Objects
Los objetos de proceso son aquellos que se originan en torno al procesamiento de un pago; por ejemplo, se produce un objeto de proceso por cada mensaje intercambiado con otro sistema a través del flujo de procesamiento del IPF.
Los objetos de proceso se asignan por defecto un identificador único, que está compuesto por la "asociación primaria" y un uuid generado aleatoriamente. Este ID único es utilizado por ODS para determinar si los objetos de proceso han sido vistos anteriormente. Por ejemplo, si un objeto se publica más de una vez, o se consume más de una vez, entonces solo existirá una única instancia en la base de datos siempre que los objetos recibidos tengan el mismo ID único.
Objetos Personalizados
| Los objetos personalizados ya no son ingeridos por ODS, pero los archivos adjuntos aún son compatibles y se almacenan en el custom colección de objetos. |
Los objetos personalizados representan datos pertenecientes a un pago que no es un ISO 20022.MDS objeto, o un objeto de proceso. Es probable que este objeto contenga customer-datos específicos relacionados con el pago.
Los objetos de datos personalizados suelen ser pares clave/valor.
Versioning
ODSmantiene la compatibilidad hacia atrás con la versión del esquema de IPF Processing Data producido por IPF. La siguiente tabla detalla las versiones.
| Versión | Compatibilidad |
|---|---|
1 |
Compatible pero obsoleto |
2 |
Soportado |
Bulk Escribe
ODS Ingestionutiliza comandos de escritura masiva al insertar documentos en la base de datos. El número de documentos que se insertan en un solo comando depende del número de Data Envelopes suministrado por IPF Processing Data Ingreso a ODS Ingestion’s BatchedIpfProcessingDataHandler implementación.
Para un rendimiento óptimo de Ingesta, puede que necesite ajustar la configuración de Ingress. Consulte el Ingress configuración de lote de ajuste documentación para más detalles.
Las métricas están habilitadas por defecto para monitorear el número de documentos que se insertan por comando de base de datos; estas deben ser utilizadas junto con las métricas de Ingress para ajustar. ODS Ingestion rendimiento. Estos pueden ser deshabilitados configurando ods.metrics.enabled = false.
Cuando esté habilitado, se emitirán las siguientes métricas:
| Nombre de la métrica | Etiquetas posibles | descripción |
|---|---|---|
|
tipo → " MDS ", " PDS ", "PROCESO", "UNIDAD_DE_TRABAJO", "RESUMEN" |
A métrica de resumen que registra el número de documentos que se están escribiendo en un solo comando de inserción. |
|
tipo → " MDS ", " PDS ", "PROCESO", "UNIDAD_DE_TRABAJO", "RESUMEN" |
A métrica de contador diseñado para rastrear la ocurrencia de excepciones de clave duplicada durante la inserción de documentos. En el contexto de la MDS, PDS, y Procesar colecciones, estas excepciones se desestiman, considerando su naturaleza de solo anexar. Sin embargo, cualquier excepción de este tipo para el UnitOfWork y las colecciones de Resumen activan las actualizaciones de documentos apropiadas |
Manejo de Errores
Cualquier error generado durante la ingestión se registra como una advertencia sin que se tome ninguna acción por defecto.
Sin embargo,ODS puede salir del evento del sistema opcional OdsIngestionFailed vía Kafka. Esto se realiza configurando lo siguiente para su ODS Ingestion instancias:
ipf.system-events.exporter.type = ipf-processing-data-egressVea el System Event Exporter documentación para más detalles.