Archivado
Archivando paquetes y exportando datos de unidad de trabajo en un estándar IPF Processing Data sobre. Solo las unidades de trabajo que han alcanzado un estado terminal serán "archivadas".
Descripción general
El comportamiento de archivo se describe en el siguiente diagrama de secuencia.

ODS Ingestionrealiza la selección de candidatos y publica esos candidatos en un ReadyForArchive notificación a un Kafka tema.
IPF Archiver consume las notificaciones, y para cada candidato dentro de ellas, obtiene todos sus datos y produce un paquete de archivo, que se publica en Kafka.
Selección de Candidatos
La selección de candidatos es donde se identifican las unidades de trabajo como listas para ser archivadas. Se realiza por ODS Ingestion, y está deshabilitado por defecto.
Los candidatos son seleccionados cuando han alcanzado un estado terminal, por ejemplo, tienen un finishedAt marca de tiempo, y que esa marca de tiempo se encuentra dentro de la ventana de selección de una hora actual.
Ventana de Selección
La ventana de selección es un período de una hora.
Se realizan consultas para unidades de trabajo que han finalizado dentro de ese período.
La ventana de selección es siempre una fecha y una hora, por ejemplo.{2023-12-18, 7} es una ventana en la 18 December 2023 con un rango de tiempo de [07:00.08:00).
El finishedAt la marca de tiempo de una unidad de trabajo debe satisfacer {finishedAt | lowerBound ⇐ finishedAt < upperBound} para ser elegible para la selección de candidatos.
Cuando todos los candidatos han sido seleccionados de una ventana, se pasa a la siguiente ventana, por ejemplo.{2023-12-18, 8}, entonces {2023-12-18, 9}, y así sucesivamente.
Al final del día, p. ej.{2023-12-18, 23}, la siguiente ventana es {2023-12-19, 0}.
El finishedAt la marca de tiempo y las consultas de la ventana de selección siempre están en UTC, por ejemplo, una ventana de selección de {2023-12-18, 9} tiene un límite inferior de 2023-12-18T09:00:00Z, y un límite superior de 2023-12-18T09:59:59.999999999Z.
Período de gracia
El período de gracia es un lapso de tiempo que la selección de candidatos esperará hasta que una unidad de trabajo sea elegible para archivo. Debe expresarse en horas o días, y el período de gracia más pequeño es de 1 hora.
El inicio del período de gracia se calcula restando el período de gracia de la hora actual.
por ejemplo, actualmente 2023-12-18T13:49:21Z, y el período de gracia es de una hora.
El límite inferior del período de gracia es la hora actual de 13, menos el período de gracia de 1 hora, lo que resulta en 2023-12-18T12:00:00Z.
Debido a que se ignoran los minutos y segundos, el período de gracia suele ser mayor que el período configurado, hasta 00:59:59.999999 más.
Comportamiento de Selección Inicial
Cuando la selección de candidatos se ejecute por primera vez, debe indicarle desde dónde comenzar, por ejemplo, la primera ventana. Si esto no está configurado explícitamente, se registrará una advertencia y la selección de candidatos fallará.
Una vez que la selección de candidatos se haya ejecutado con éxito al menos una vez, esta configuración no tendrá efecto.
Fecha
La ventana inicial puede ser una fecha de inicio configurada, que siempre es al comienzo de ese día, por ejemplo, una fecha de 2023-12-01 resulta en una ventana inicial de {2023-12-01, 0}.
Último
Toma la fecha y hora actuales, resta el período de gracia y comienza a la hora anterior a esa.
Si actualmente es 2023-12-18T13:49:21Z, la hora actual es 13. Reste el período de gracia, por ejemplo, 1 hora, lo que resulta en 12, y comience desde la hora anterior a esa, 11. La ventana inicial es {2023-12-18, 11}.
Visualización
Dado que la hora actual es 15:15, el período de gracia es 4-hours, o [11:00.15:15], y la ventana de selección actual es [9.10).
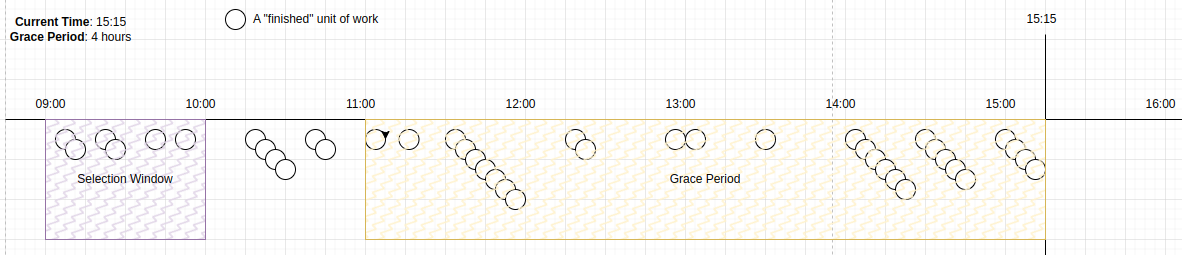
Una vez que todos los candidatos en la ventana de selección han sido seleccionados, lo cual puede ser en una única consulta o en muchas consultas más pequeñas, la ventana se mueve a [10.11).
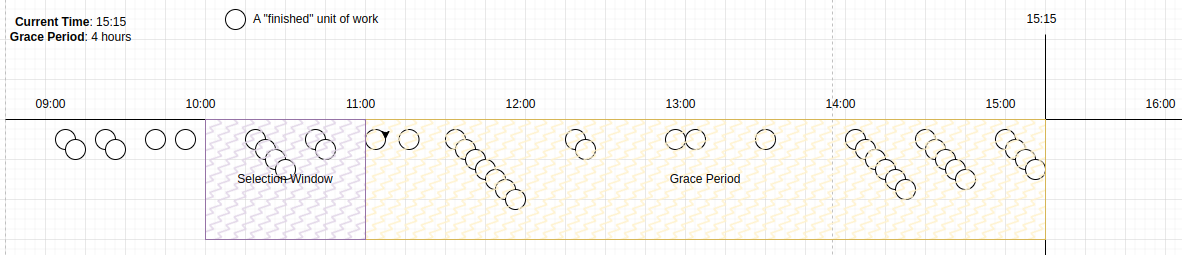
Una vez que todos los candidatos en la ventana de selección han sido seleccionados, la ventana se mueve a [11.12).
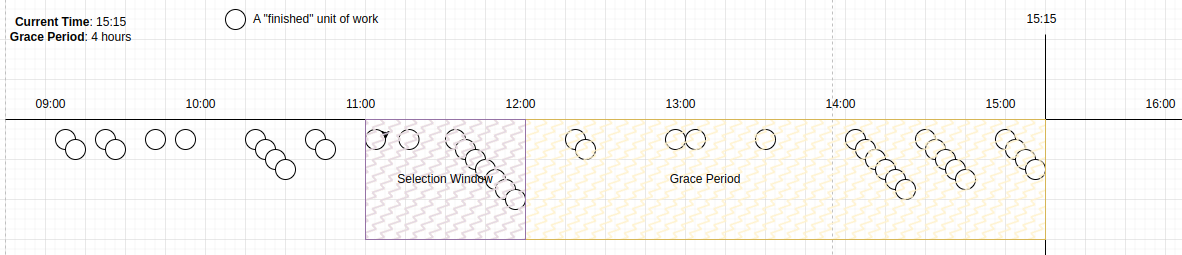
Esta ventana de selección se encuentra ahora dentro del período de gracia. No se seleccionan candidatos hasta que el tiempo avanza, de tal manera que la ventana de selección esté fuera del período de gracia.
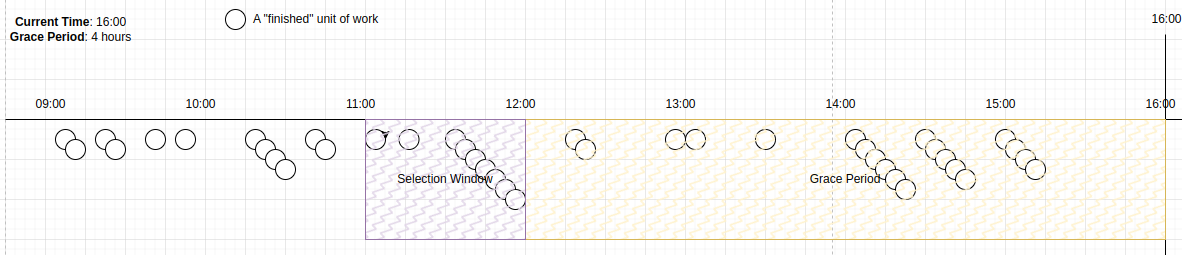
Cuando la hora actual llegue a 16:00, el período de gracia se convierte en [12:00.16:00], y la ventana de selección [11:00.12:00) se vuelve elegible.
Los candidatos dentro de esta ventana serán seleccionados ahora.
Listo para archivar Notifications
Los candidatos que son seleccionados para archivo se publican en un ReadyForArchive notificación, que contiene los candidatos seleccionados, la ventana en la que fueron seleccionados y su número de secuencia dentro de la ventana de selección actual.
Cada notificación indicará si es la última notificación para la ventana actual.
Ejemplos
Si hay tres candidatos para la hora 12, y el tamaño de recuperación es 2, las siguientes notificaciones podrían ser enviadas.
{
"candidates": ["unit-of-work-1", "unit-of-work-2"],
"window": {
"date": "2023-12-18",
"hour": 12,
"notificationSequence": 1
},
"lastNotificationInWindow": false
}{
"candidates": ["unit-of-work-3"],
"window": {
"date": "2023-12-18",
"hour": 12,
"notificationSequence": 2
},
"lastNotificationInWindow": true
}Si no hay candidatos para la hora 13, se enviaría la siguiente notificación.
{
"candidates": [],
"window": {
"date": "2023-12-18",
"hour": 13,
"notificationSequence": 1
},
"lastNotificationInWindow": true
}State
El estado de selección de candidatos se crea en la primera ejecución y se actualiza en cada ejecución subsiguiente.
El estado inicial podría parecerse a..
{
"date": "2023-12-18",
"hour": "12",
"checkpoint": null,
"notificationSequence": 1
}La fecha y la hora representan la ventana de selección actual.
El punto de control es el último candidato que vimos dentro de la ventana.
La secuencia de notificación es un número que se incrementa en cada ejecución hasta que se avanza la ventana, momento en el cual vuelve a ser 1.
Cuando se seleccionan candidatos para este estado, se actualiza.
{
"date": "2023-12-18",
"hour": "12",
"checkpoint": "unit-of-work-6",
"notificationSequence": 2
}Si no hay más candidatos en la ventana, pasamos a la siguiente ventana.
{
"date": "2023-12-18",
"hour": "13",
"checkpoint": null,
"notificationSequence": 1
}Configuración
- IMPORTANTE
-
La siguiente configuración de selección de candidatos debe aplicarse a ODS Ingestion instancias de aplicación.
La selección de candidatos se ejecuta con frecuencia y selecciona un número máximo de candidatos en cada ejecución. Puede controlar el rendimiento de la selección de candidatos configurando tanto la frecuencia de ejecución como el tamaño de recuperación para cada ejecución.
Todas las propiedades de configuración están precedidas por ipf.archiver.candidate-selection.
Configuración de Selección de Candidatos por Defecto
ipf {
archiver {
candidate-selection {
enabled = false
# Define what should happen when candidate selection is executed for the first time
initial-execution-behaviour {
# Define the initial window for candidate selection, e.g. the time period in which to search for finished unit of works.
# LATEST = The latest window given the current datetime and the grace period
# DATE = Define a specific date with a `start-date` property, e.g. `start-date = 2023-11-01`
# UNDEFINED = The default. Candidate selection will fail if this property is used on the first execution
window = UNDEFINED
# An example start-date when a specific date is used (window = DATE) for the initial window
# start-date = 2023-11-01
}
# Minimum time to wait before selecting a candidate unit of work once it has reached a terminal state
grace-period = 2H
# How many archive candidates to fetch on each invocation of the scheduler (see scheduler config below)
fetch-size = 1000
# Journey types to select for archive. If null or empty, then any journey type will be archived
eligible-journey-types = []
scheduler {
# How long to wait once ODS has started before checking for archive candidates
initial-delay = 1M
# How often to check for archive candidates, fetching `fetch-size` candidates each time. See `fetch-size` above.
frequency = 10s
restart-settings {
min-backoff = 1s
max-backoff = 1s
jitter-factor = 0.2
}
}
}
}
}| Propiedad | Predeterminado | Descripción |
|---|---|---|
|
|
Permite la selección de candidatos, que está desactivada por defecto. |
|
|
Un período de tiempo expresado en horas, por ejemplo. |
|
|
El número máximo de candidatos a seleccionar cada vez que se ejecute la selección de candidatos. |
|
|
Define los tipos de unidad o trabajo que son elegibles para archivo. Por defecto, todos los tipos de unidad de trabajo serán archivados. Configurando con |
Comportamiento de Ejecución Inicial
Todas las propiedades de configuración están precedidas por ipf.archiver.candidate-selection.initial-execution-behaviour.
| Propiedad | Predeterminado | Descripción |
|---|---|---|
|
|
Ya sea |
|
La fecha de inicio de la ventana de ejecución inicial, por ejemplo, |
Programador
Todas las propiedades de configuración están precedidas por ipf.archiver.candidate-selection.scheduler.
| Propiedad | Predeterminado | Descripción |
|---|---|---|
|
|
El período de tiempo que debe esperar una vez que la aplicación ha comenzado antes de comenzar a buscar candidatos para el archivo. Por defecto, espera 1 minuto. |
|
|
Con qué frecuencia se ejecuta la selección de candidatos. Por defecto, es cada 10 segundos. |
La configuración de los ajustes del supervisor de manejo de errores del programador se encuentra bajo ipf.archiver.candidate-selection.scheduler.restart-settings.
| Propiedad | Predeterminado | Descripción |
|---|---|---|
|
|
|
|
|
|
|
|
Exportador de Selección de Candidatos
- IMPORTANTE
-
La siguiente configuración del exportador de selección de candidatos debe aplicarse a ODS Ingestion instancias de aplicación.
ODS Ingestionproduce candidatos para archivar a Kafka.
Configuración del exportador de selección de candidatos predeterminada
ipf.archiver.candidate-selection {
# Archiver connectors disabled by default
enabled = false
exporter {
# Default resiliency settings applied to the exporter SendConnector
resiliency {
max-attempts = 5
minimum-number-of-calls = 10
initial-retry-wait-duration = 1s
}
kafka {
# Kafka producer config specifying topic, client id and restart-settings for the exporter KafkaConnectorTransport
producer {
topic = IPF_ARCHIVER_CANDIDATES
restart-settings = {
min-backoff = 1s
max-backoff = 5s
random-factor = 0.25
max-restarts = 5
max-restarts-within = 10m
}
kafka-clients {
client.id = ipf-achiver-candidate-exporter-client
}
}
}
}
}Agrupación de Archivos
Los paquetes de archivo se producen como IPF Processing Data sobres que contienen datos para una única unidad de trabajo. Los datos se construyen consultando el ODS base de datos directamente.
ODSconsume IPF Processing Data sobres, y transforma y persiste en su propio modelo de datos. La archivación toma el ODS modelo y se transforma de nuevo en el IPF Processing Data modelo.
Los paquetes de archivo se producen en IPF Processing Data esquema V2 por defecto.
Los paquetes de archivo también se producen sin una vista de resumen relacionada con la unidad de trabajo por defecto. Esto puede cambiarse configurando ipf.archiver.bundle.include-summary = true esto incluirá la vista resumen en un custom representación de objeto.
A continuación se presenta una representación de la custom objeto que contiene la vista de resumen. Mientras que la vista de resumen es una cadena, puede ser deserializada en un objeto desde el ODS Inquiry API specification. El exacto ODS Inquiry el objeto de esquema se definirá en el key campo. En el ejemplo a continuación, el ODS Inquiry el objeto de esquema utilizado es el SummaryView.
Ejemplo de Resumen de Objeto Personalizado
{
"key" : "SummaryView",
"value" : "{\"class\":\"SummaryView\",\"createdAt\":\"2023-12-04T11:00:00Z\",\"unitOfWorkId\":\"unit-of-work-3\",\"terminal\":false,\"failure\":false,\"clientRequestId\":\"KNOWN\",\"processingEntity\":\"processing-entity-3\"}",
"uniqueId" : "a91e3f60-0da6-49e8-bdec-958c51218bb9",
"createdAt" : "2025-03-14T15:08:31.440Z"
}Datos
No todos los datos recibidos por ODS lo incluye en el paquete de archivo. En algunos casos, los datos se ignoran completamente; en otros casos, solo se incluye la última versión de un objeto particular. Los datos que no pertenecen a una unidad de trabajo son ignorados.
| Datos ODS | ¿Incluido en el paquete? | Notas |
|---|---|---|
Message Log |
sí |
|
Process Flow Event |
sí |
|
MDS |
sí |
Todas las versiones de todos MDS se incluyen objetos |
PDS |
sí |
Todas las versiones de todos PDS se incluyen objetos |
Objeto Personalizado |
sí |
Todo custom se incluyen objetos, así como un custom representación de objeto de la vista de resumen relacionada con la unidad de trabajo, si está habilitada. |
System Event |
no |
Los eventos del sistema para una unidad de trabajo son ignorados. |
Process Flow Definición |
no |
Process Flow Definitions no pertenecen a una unidad de trabajo |
Manejo de Errores
Cualquier error generado durante la agrupación de archivos se registra como un error sin que se tome ninguna acción.
Sin embargo, el Archiver puede egresar el evento del sistema opcional.ArchiveBundlingFailed a través de Kafka. Esto se realiza configurando lo siguiente para sus instancias de IPF Archiver:
ipf.system-events.exporter.type = ipf-processing-data-egressVea el System Event Exporter documentación para más detalles.
IPF Archiver
IPF Archiver es una aplicación ejecutable que consume ReadyForArchive notificaciones, y construye y exporta paquetes de archivo para cada candidato que contiene.
IPF Archiver debe ser implementado junto con un ODS Ingestion instancia. ODS Ingestionrealizará la selección de candidatos y enviará notificaciones.
Tanto IPF Archiver como ODS Ingestion compartirá una instancia de base de datos.
Selección de Candidatos Consumidor
Los candidatos para el archivo se consumen de Kafka.
Configuración
- IMPORTANTE
-
La siguiente configuración de consumo de candidatos debe aplicarse a las instancias de la aplicación IPF Archiver.
Configuración del consumidor de selección de candidatos predeterminada
ipf.archiver.candidate-selection.consumer {
# Default resiliency settings applied to the consumer ReceiveConnector
resiliency {
max-attempts = 30
}
kafka {
# Kafka consumer config specifying topic, group id and restart-settings for the consumer KafkaReceiveConnectorTransport
consumer {
topic = IPF_ARCHIVER_CANDIDATES
restart-settings = {
min-backoff = 1s
max-backoff = 5s
random-factor = 0.25
max-restarts = 5
max-restarts-within = 10m
}
kafka-clients {
group.id = ipf-achiver-candidate-consumer-group
}
}
}
}Exportador de Paquetes de Archivo
Los paquetes se exportan a Kafka.
Configuración
- IMPORTANTE
-
Toda la configuración de agrupación de archivos debe aplicarse a las instancias de la aplicación IPF Archiver.
Configuración predeterminada del exportador de paquetes de archivo
ipf.archiver.bundle.exporter {
# Default resiliency settings applied to the exporter SendConnector
resiliency {
max-attempts = 5
minimum-number-of-calls = 10
initial-retry-wait-duration = 1s
}
kafka {
# Kafka producer config specifying topic, client id and restart-settings for the exporter KafkaConnectorTransport
producer {
topic = IPF_ARCHIVER_BUNDLES
restart-settings = {
min-backoff = 1s
max-backoff = 5s
random-factor = 0.25
max-restarts = 5
max-restarts-within = 10m
}
kafka-clients {
client.id = ipf-achiver-bundle-exporter
compression.type = gzip
}
}
}
}Consumo de Paquetes de Ipf Archiver
Para consumir los paquetes de archivo, usted deberá implementar com.iconsolutions.ipf.archiver.bundle. IpfArchiverBundleHandler y regístrelo como una Spring bean. Además, deberá depender del módulo 'ipf-archiver-bundle-consumer' que instancia un receive connector para el IPF_ARCHIVER_BUNDLES tema de kafka.
ipf-archiver-bundler-api`proporciona el `IpfArchiverBundleHandler interfaz:
<dependency>
<groupId>com.iconsolutions.ipf.archiver</groupId>
<artifactId>ipf-archiver-bundler-api</artifactId>
</dependency>
ipf-archiver-bundler-consumer provides a predefined receive connector for the IPF_ARCHIVER_BUNDLES kafka topic. This connector uses IpfArchiverBundleHandler to handle the received bundles:
This dependency will also pull in ipf-archiver-bundler-api as a transitive dependency
|
<dependency>
<groupId>com.iconsolutions.ipf.archiver</groupId>
<artifactId>ipf-archiver-bundler-consumer</artifactId>
</dependency>
Configuración
Configuración predeterminada del paquete de archivo para consumidores
ipf.archiver.bundle.consumer {
resiliency {
max-attempts = 30
}
kafka {
# Kafka consumer config specifying topic, group id and restart-settings for the consumer KafkaReceiveConnectorTransport
consumer {
topic = IPF_ARCHIVER_BUNDLES
restart-settings = {
min-backoff = 1s
max-backoff = 5s
random-factor = 0.25
max-restarts = 5
max-restarts-within = 10m
}
kafka-clients {
group.id = ipf-achiver-bundle-consumer-group
}
}
}
}