DSL 1 - Introducción al DSL de Icon
Visión general
Encontrarás el siguiente vídeo (10 minutos) como una introducción muy útil a la estructura básica de una aplicación IPF. También ofrece una visión general de alto nivel de los conceptos del DSL tratados en esta sección del tutorial.
Conceptos
|
Esta sección del tutorial introduce los conceptos dentro del DSL de pagos de Icon. Es un recorrido teórico y no requiere acceso a componentes de IPF. |
Datos de negocio
Empezamos considerando los datos. Los datos son lo que impulsa el procesamiento y la toma de decisiones en todo IPF.
El primer concepto a considerar es el "Business Data Element" (elemento de datos de negocio). Tiene cuatro propiedades:
-
Un nombre
-
Una descripción
-
Un "tipo de datos": el tipo de datos puede ser cualquier tipo de Java, ya sea clases estándar como String, Integer, etc., o tus propios tipos a medida.
-
Una "categoría de datos": un campo opcional; los valores posibles son un conjunto enumerado que hace referencia al tipo de dato representado por este BusinessDataElement. Esta etiqueta de categoría de datos es utilizada por varios componentes de IPF, como IPF Data Egress y el Operational Data Store, que pueden registrar automáticamente los datos capturados de los flujos de proceso, según la categoría de datos. Hay cuatro categorías principales:
-
MESSAGE_DATA_STRUCTURE: datos que se originan en mensajes financieros externos que a menudo se modelan como componentes de mensajes ISO20022 dentro de IPF.
-
PROCESSING_DATA_STRUCTURE: datos recopilados durante el procesamiento de pagos, como metadatos e información del tipo de pago.
-
ADDITIONAL_IDENTIFIER: se aplica a elementos que representan identificadores adicionales asociados al pago.
-
Cualquier proyecto MPS puede tener tantos elementos de datos de negocio como necesites. Estos elementos se definen dentro de una "Business Data Library" (biblioteca de datos de negocio), que no es más que una colección de datos relacionados, y se pueden definir tantas bibliotecas como se necesiten.
|
IPF proporciona varias bibliotecas de datos de negocio preconfiguradas. Por defecto, a cualquier proceso se le asigna la biblioteca "error", que proporciona elementos por defecto para gestionar fallos del flujo, a saber:
Los conceptos de códigos de razón y de respuesta se tratan más adelante en este documento. |
Durante la vida de un pago, cada elemento de datos de negocio es único y puede actualizarse según sea necesario.
Flujo
El procesamiento de un pago lo realiza un "Flujo". Un flujo representa un único proceso de negocio de extremo a extremo y está diseñado para especificar la vida de un pago. Un único flujo puede tener muchos caminos, cada uno representando una forma distinta de procesar un pago individual en función de los datos proporcionados. Un flujo contiene varias cosas:
-
Un nombre
-
Una descripción
-
Una versión
-
Un conjunto de estados globales
-
Una lista de "States"
-
Una lista de "Events"
-
Un "Initiation Behaviour"
-
Una lista de "Input Behaviours"
-
Una lista de "Event Behaviours"
-
Una lista de "Aggregate Functions"
Una definición de cada uno de estos aspectos se describe en las siguientes secciones.
|
La combinación de "Flow Name" y "Flow Version" identifica de forma única un flujo. La versión es un identificador numérico opcional; por ejemplo, un flujo puede llamarse "Test" y tener la versión 3; entonces se identificará de forma única como "TestV3". Si no hubiera versión definida, se identificaría simplemente por el nombre "Test". Este identificador se conoce como "FlowId". |
Estados globales
Primero consideramos el "Global State Set". El conjunto de estados globales es un conjunto de estados que representan el estado global de un pago. Se utiliza especialmente cuando un pago puede abarcar múltiples flujos (por ejemplo, si el procesamiento se divide en partes de "iniciación" y "ejecución"), pero también puede aplicar un estado de agrupación general a las partes individuales del flujo para simplificar las transiciones de estado a nivel de pago. Cada estado a nivel de flujo puede mapearse a un estado global, de modo que múltiples estados de flujo puedan considerarse como si dejaran el pago en el mismo estado global general.
|
Se proporciona un conjunto de estados globales por defecto, con los estados estándar: Pending, Accepted, Rejected, Manual Action Required y Cancelled. |
Estados
El siguiente concepto dentro de nuestro flujo es un "State". Es, sencillamente, un punto de reposo en el flujo por el que el pago puede pasar en su recorrido; por ejemplo, podemos tener un flujo muy simple que vaya de "State A" a "State B".
Un estado tiene varias propiedades:
-
Un nombre
-
Una descripción
-
Un estado global
-
Una marca de terminalidad (terminal flag): se utiliza para indicar que esto termina el flujo al que pertenece el estado.
Cada flujo puede contener muchos estados distintos.
Eventos
Cuando un flujo pasa de un estado a otro, se denomina "State Transition". En IPF, para que se produzca una transición de estado, el sistema debe recibir un "Event" durante el recorrido de procesamiento del pago. En este caso, es en realidad un tipo específico de evento conocido como "Domain Event". Un evento de dominio es una ocurrencia fáctica y persistida: la llegada de un evento significa que algo explícito ha ocurrido y puede causar algún cambio en el procesamiento de nuestro pago.
Un evento tiene varias propiedades:
-
Un nombre
-
Una descripción
-
Una lista de elementos de datos de negocio
Cuando se forma un evento, el sistema comprobará su propio comportamiento para determinar qué acciones deben realizarse. Si bien este comportamiento se explora más adelante en este documento, vale la pena señalar aquí que hay tres ocasiones en las que un evento puede provocar un cambio en el procesamiento; se conocen como condiciones de "Event Criteria" y se definen como:
-
On: este movimiento ocurrirá cuando llegue un único evento (por ejemplo, podemos transicionar al recibir "Event 1").
-
On any of: este movimiento ocurrirá cuando llegue uno de múltiples eventos (por ejemplo, podemos transicionar al recibir cualquiera de "Event 1" o "Event 2").
-
On all of: este movimiento solo ocurrirá cuando lleguen múltiples eventos (por ejemplo, podemos transicionar solo después de recibir tanto "Event 1" como "Event 2").
|
Aquí hemos descrito el "Domain Event", que es el tipo de evento que se declara explícitamente dentro de cualquier solución MPS. Sin embargo, IPF en su conjunto utiliza varios tipos diferentes de eventos:
Todos estos tipos de eventos se tratan más adelante en este documento. |
Dominios externos
Después de procesar un evento, la aplicación puede realizar una o más actividades para determinar qué sucede a continuación con un pago. Por ejemplo, al recibir "Event A" podríamos querer hacer una validación y llamar a otra aplicación para que valide nuestros datos.
Para apoyar este procesamiento posterior al evento, el concepto más importante es el "External Domain". Representa algún dominio de negocio —no el del flujo actual— con el que necesitamos interactuar.
Por ejemplo, supongamos que necesitamos hablar con un sistema de sanciones en una parte del flujo. Para ello, modelaríamos ese sistema de sanciones como un dominio externo.
Cada dominio externo consta de los tres tipos de interacción que podemos realizar con él:
-
"Instructions": son lo más simple que recibimos de un dominio externo. Puede ser disparado por el dominio externo en cualquier momento y comenzaremos a procesar. Puede entenderse como que el dominio externo nos empuja información.
-
"Notifications": son lo opuesto a las instrucciones. Se usan cuando queremos empujar nuestros datos a un dominio externo.
-
"Requests": se usan cuando necesitamos una "respuesta" del dominio externo a nuestra petición.
Instrucciones
Primero consideremos la instrucción. Pueden ser iniciadas por un sistema externo y contienen las siguientes propiedades:
-
Un nombre
-
Una descripción
-
Una lista de "Business Data Elements"
Cuando la aplicación IPF recibe una instrucción, generará un evento correspondiente (la decisión de qué evento generar se describe más adelante). Los datos de negocio del evento se rellenan con todos los elementos de datos de negocio coincidentes.
Notificaciones
A continuación, la notificación; como una instrucción, tiene las siguientes propiedades:
-
Un nombre
-
Una descripción
-
Una lista de "Business Data Elements"
Cuando la aplicación IPF envía una notificación, rellenará en ella todos los elementos de datos de negocio para los que tenga un registro coincidente.
Peticiones
Por último, consideramos las peticiones. La petición puede entenderse como dos partes: la propia petición y la respuesta correspondiente.
La parte de petición contiene:
-
Un nombre
-
Una descripción
-
Una lista de datos de negocio
-
Una lista de respuestas
La parte de respuesta es ligeramente diferente y tiene algunas características nuevas a considerar:
-
Un nombre
-
Una descripción
-
Una lista de datos de negocio
-
Un "conjunto de códigos de respuesta": es un grupo de códigos de respuesta. Un "Response Code" es un código de resultado esperado para una respuesta que podría usarse para el procesamiento posterior. En términos ISO, es análogo a un Status.
-
Un "conjunto de códigos de razón": es un grupo de códigos de razón. Un "Reason Code" es el motivo por el que la respuesta es la que es. Por ejemplo, tu código de respuesta podría ser "Rejected" con una razón "Incorrect Currency". En términos ISO, un código de razón es análogo a un Status Reason.
-
Una marca de finalización (completing flag): define si la petición debe considerarse completada cuando llega esta respuesta. Por ejemplo, en una petición donde el sistema externo envía un acuse técnico seguido de una respuesta de negocio final, definiríamos dos respuestas: una para representar el acuse técnico (no completante) y otra para la respuesta de negocio (completante).
|
En términos ISO, un código de respuesta es análogo a un "Status", mientras que un código de razón es análogo a un "Status Reason". |
|
El sistema proporciona por defecto un conjunto de códigos de respuesta "AcceptOrReject" para respuestas estándar de tipo aprobar / rechazar. También proporciona un conjunto con todos los códigos de razón ISO. |
Ahora unimos estos elementos y formamos la base de cualquier flujo:

Aquí vemos que cuando IPF recibe algo de un dominio externo (una instrucción o una respuesta), se genera un evento que puede provocar una transición de estado, seguida de la invocación de una notificación o petición a un dominio externo.
Funciones de dominio
Es posible que no queramos llamar a un dominio externo para continuar procesando nuestro flujo. Esto puede ocurrir porque sabemos qué hacer a continuación o podemos calcularlo. Para ello, hay dos conceptos más a considerar:
En este caso, una opción es usar la capacidad "Domain Function" que ofrece el propio flujo. Funciona de forma muy similar a un par petición/respuesta en una llamada a un dominio externo, salvo que en el caso de una función de dominio la propia aplicación IPF es un dominio, por lo que la llamada permanece interna (por ejemplo, crear un dominio externo que represente nuestro flujo actual funcionaría igual que una función de dominio, pero sería una mala representación de la lógica de control real). Así que, cuando llamamos a una función de dominio, esperamos recibir una respuesta y luego esa respuesta se transformará en un evento que podrá provocar procesamiento posterior.
Al igual que una petición, la función de dominio tiene varias propiedades:
-
Un nombre
-
Una descripción
-
Una lista de datos de negocio
-
Una lista de respuestas
Eventos adicionales
La segunda opción es un "Additional Event" (evento adicional): también pueden usarse para avanzar el flujo.
Cuando se genera un evento adicional, el sistema lo procesará como si hubiera sido recibido en la aplicación a través de una instrucción o una respuesta.
Añadámoslos a nuestro diagrama:

Decisiones
¿Y si queremos ejecutar lógica condicionalmente? Por ejemplo, puede que solo queramos ejecutar una comprobación de fraude si el valor del pago es superior a 50 £. En este caso podemos usar una "Decision".
Una decisión nos permite ejecutar lógica y, posteriormente, tomar rutas de procesamiento diferentes en función del resultado de esa decisión. Una decisión tiene varias propiedades:
-
Un nombre
-
Una descripción
-
Una lista de datos de negocio: son los datos que se envían al llamar a la decisión para que pueda procesar en base a ellos.
-
Una lista de "Decision Outcomes": son los posibles resultados de ejecutar la decisión; cada decisión puede tener tantos resultados distintos como sea necesario y estos resultados son propios de la decisión. Se definen simplemente proporcionando un nombre.
Las decisiones se almacenan dentro de una "Decision Library". Las bibliotecas son independientes del flujo y, por tanto, la misma decisión puede usarse en múltiples flujos.
Podemos usar una decisión en dos lugares:
-
Para determinar qué evento debe generarse en respuesta a una entrada (respuesta o instrucción)
-
Para determinar qué acciones deben realizarse después de una transición de estado
Añadamos esto a nuestro diagrama:

| Se generará también un tipo especial de evento, "Decision Outcome Event", para que el hecho de que se ha invocado la decisión y devuelto un resultado quede auditado y pueda usarse en el procesamiento posterior. |
Funciones de agregado
Otra utilidad útil a considerar es la "Aggregate Function" (función de agregado). Una función de agregado es una pieza de lógica que puede ejecutarse tras la recepción de un evento para realizar algún tipo de cálculo sobre los datos recibidos. Estos datos se consideran "en vuelo" y, por lo tanto, no se persisten en la aplicación.
Un buen ejemplo es un contador que registra cuántas veces ha ocurrido algo durante un flujo: cada vez que se llama a la función, se puede actualizar ese contador. El resultado de la función de agregado pasa a estar disponible más adelante en el flujo.
Otro buen caso de uso es realizar un mapeo de datos para transformar los datos en algo que pueda usarse aguas abajo.
Añadamos la función de agregado a nuestro diagrama:

Comportamientos (Behaviours)
Los siguientes conceptos a considerar son dos tipos de agrupación. Para separar la lógica que necesitamos cuando procesamos una entrada al sistema (desde una respuesta o instrucción) y generamos el evento, de la lógica requerida al procesar el comportamiento del sistema basado en ese evento, tenemos dos conceptos de agrupación:
-
"Input Behaviour": es el comportamiento que especifica para cada entrada qué evento se generará.
-
"Event Behaviour": es el comportamiento que especifica qué acciones deben realizarse al recibir un evento.
Input Behaviour
Un input behaviour tiene varias propiedades:
-
Una entrada: es la entrada (instrucción o respuesta) que dispara el comportamiento.
-
Un código de respuesta: es el código de respuesta (vinculado a la respuesta si la entrada es una respuesta; en caso contrario, este campo no aplica) para el que el comportamiento aplica.
-
Un evento: puede ser un evento directamente o a través de la ejecución y el resultado de una decisión.
| Ten en cuenta que, cuando se usan códigos de respuesta, si no se define uno en un input behaviour, este se considerará el comportamiento "por defecto" para todos los códigos de respuesta. |
Event Behaviour
El event behaviour es algo más complejo. Tiene varias propiedades:
-
Un "Estado actual" (Current State): es el estado en el que el flujo debe estar para que el comportamiento aplique.
-
Un "Criterio": cuándo aplica el comportamiento (on / on all of / on any of).
-
Una lista de eventos: uno o más eventos; pueden ser de cualquier tipo (p. ej., domain, timeout, etc.).
-
Un "Move to State": el estado de destino del comportamiento.
-
Una lista de acciones: son las acciones que deben ejecutarse después de la transición de estado; p. ej., peticiones, notificaciones, etc.
Actualicemos nuestro diagrama para mostrar esto:
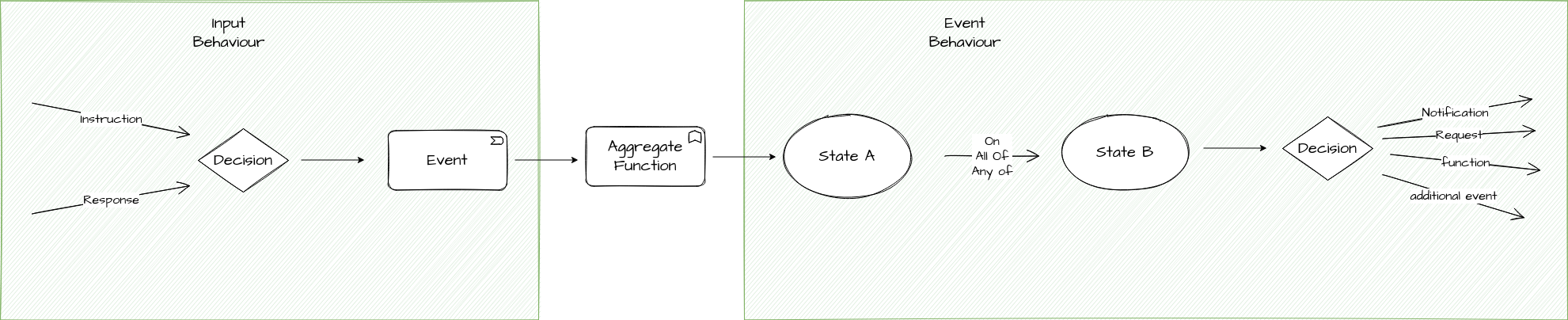
| Ten en cuenta que la función de agregado, como unidad autocontenida de cálculo, no se considera ni event behaviour ni input behaviour, sino una capacidad funcional propia. |
Initiation Behaviour
Hay un tipo más de comportamiento clave a considerar: el "Initiation Behaviour". Es una versión especializada del input behaviour anteriormente definido, pero se usa solo para iniciar un flujo. No está vinculado a un dominio externo, por lo que podemos iniciar el flujo potencialmente desde muchas fuentes distintas.
Un initiation behaviour tiene varias propiedades:
-
Una lista de datos de negocio
-
Un estado inicial al que moverse
-
Una lista de acciones a realizar
|
Ten en cuenta que, cuando se invoca el initiation behaviour, se inicia un flujo y se generará el evento "FlowInitiated". |
Ya hemos revisado todos los componentes que forman un único flujo.
Subflujos
Lo siguiente a considerar son segmentos del flujo reutilizables.
Por ejemplo, considera una comprobación de sanciones que podría necesitarse en varios lugares del flujo. Podríamos especificar cada sección del flujo por separado y escribir la lógica cada vez, pero lo ideal sería poder reutilizar la lógica común. Aquí es donde se introduce el concepto de "Subflow".
Un subflujo es un componente de flujo reutilizable. Es esencialmente igual que un flujo en que tiene estados, input behaviours y event behaviours. Sin embargo, un subflujo no tiene vida propia y solo se usa como mecanismo de reutilización y, por tanto, DEBE estar contenido dentro de un flujo exterior. Al llamar a un subflujo, es muy similar en comportamiento a recibir un evento:
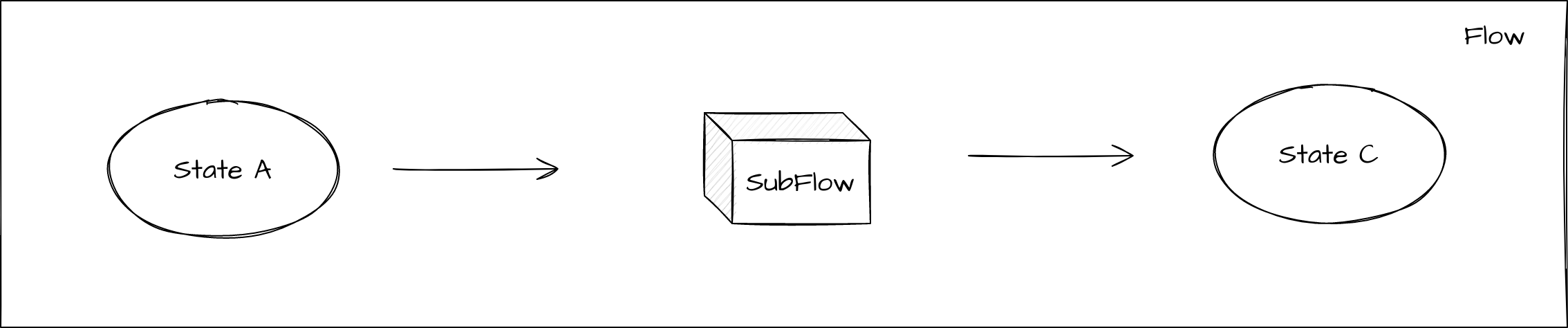
Lo clave a entender aquí es que, en lugar de movernos a un estado y luego llamar a una acción como en el procesamiento normal, aquí nos movemos a un pseudoestado que actúa como punto de entrada en el subflujo. El "control" del flujo se cede al subflujo; a partir de ese momento, procesará sus input y event behaviours hasta que alcance un estado terminal en el subflujo. Cuando alcanza un estado terminal, el control vuelve al flujo que lo llamó con un resultado que es el nombre del estado terminal. Esto puede utilizarse para el procesamiento posterior.
Ten en cuenta que, para lograr la reutilización del subflujo en múltiples lugares, cuando un subflujo se coloca dentro de un flujo principal, sus estados se mostrarán como "<subflowid> <subflow state name>", donde <subflowid> es el nombre del pseudoestado del flujo llamante y <subflow state name> es el nombre del estado dentro del subflujo.
Llamadas a flujos (Flow Calls)
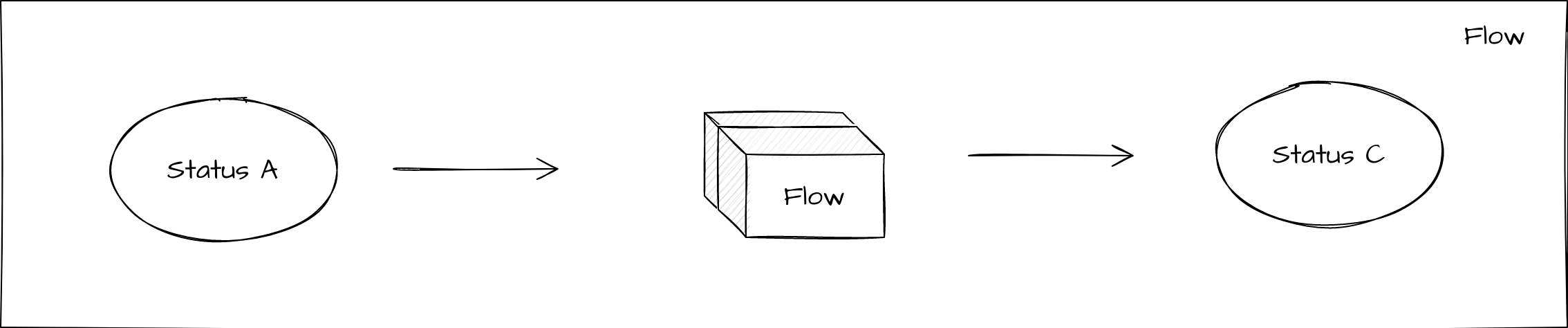
Finalmente, también es posible llamar directamente a un flujo desde otro. En este caso, el control se cede al flujo secundario y se espera un resultado de ejecución de vuelta. El flujo hijo puede informar al flujo padre de que ha alcanzado cualquier estado. Lo más común es que esto ocurra cuando se alcanza un estado terminal y el flujo hijo ha terminado el procesamiento, pero también permite realimentación desde el flujo hijo para estados intermedios antes de que finalice. Esto ofrece la posibilidad de pasar el control de ida y vuelta entre hijo y padre según sea necesario.
Conclusiones
En esta sección hemos tratado los conceptos centrales que forman el DSL de pagos de Icon y cómo encajan entre sí. Estos conceptos serán clave a partir de ahora y las siguientes secciones de esta serie de tutoriales nos irán mostrando cómo usar distintos de ellos para crear nuestra aplicación de pagos.