Application Resilience via Akka Cluster Sharding
Introduction
This document exists to communicate how IPF applications use Akka Cluster Sharding for recovery and resilience. This is not a deep dive into Akka Cluster Sharding and references for further reading are provided. The key thing to keep in mind whilst reviewing and understanding how IPF provides resiliency and recovery, is that IPF makes use of the Akka features and an IPF flow is merely an entity within an Actor system.
Akka Cluster Sharding
Akka Cluster Sharding works by allowing an application to scale across multiple nodes (application instance), distributing entities (flows in IPF) across several nodes in a cluster, sending messages to them via a unique ID but not having to care on which node the entity lives in the cluster. This last point is crucial to how Akka provides resiliency and can transparently move an entities location to another node on failure.
Definitions
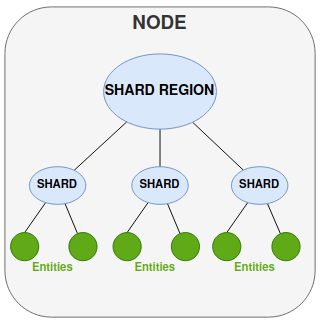
Entity - for our discussion an entity is the equivalent of an instance of an IPF Flow (i.e. the instance of an IPF flow processing a particular unique transaction).
Shard - A shard is a group of entities that will be managed together.
Shard Region - Acts as mediator for shards and handles the routing of messages to the correct entity, either to one of its shards or via another shard region on another nodes.
Node - Runtime environment for your IPF application (usually a pod within a containerised environment).
Persistence - the storing of the entities state by recording all its events.
Key Points
-
Sharding means that actors with an identifier, called entities, can be automatically distributed across multiple nodes in the cluster.
-
Each entity actor (IPF flow instance) runs only at one place.
-
Messages to be processed by an entity can be sent to the entity (IPF flow instance) without requiring the sender to know the physical location of the destination actor.
-
The physical location of the entity can change over time.
-
Persistence is used together with Cluster Sharding to recover the state of an entity (IPF Flow) after it has been moved.
-
Since Akka persistence is based on a single-writer principle only one persistent actor is active anywhere within the cluster.
-
Cluster sharing also helps with scaling to allow distribution of many stateful actors across more than one processing unit (typically a pod).
| The following scenarios talk a lot about how Akka clustering is working in IPF because its core functionality under pins how flows are managed. Where you read the word "entity" interchange with "IPF flow instance". |
BAU Cluster Operation
Consider a typical deployment of your IPF payment processing application (a Springboot application wrapping the IPF flow/s, run within a pod). In this example we have 3 nodes (3 instances of the pod).
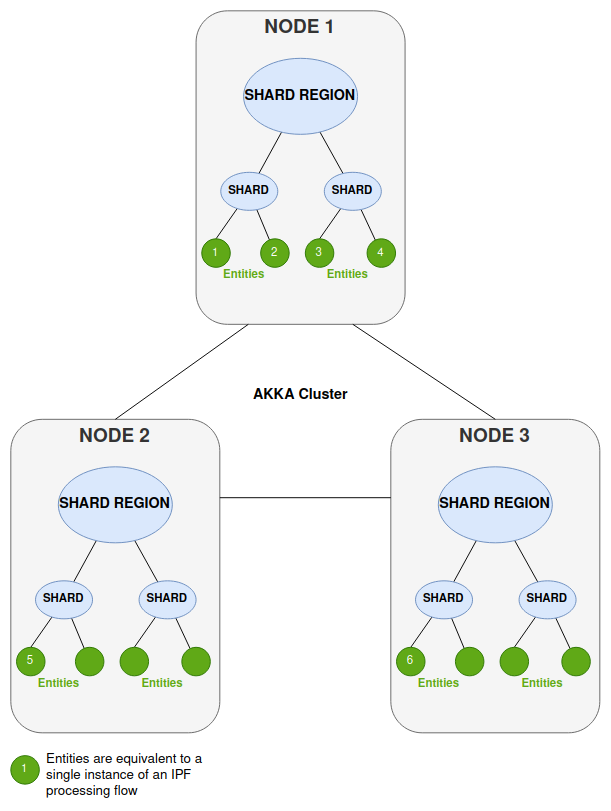
Only one instance of an entity runs in the cluster at any one time, but incoming messages may well arrive on different nodes.
So for example where a message arrives at a Shard Region but the location of that entity is in another region on a separate node, the message is routed within the Akka Cluster to the correct shard to be processed by the unique entity (IPF flow instance). In the diagram below the following things are happening when a message is processed on a specific node
-
Node 2 receives the message which is for entity/flow ID=6
-
The Shard Region (SR) on Node 2 does not have that entity within any of its shards (entity ID=6 is not running on Node 2)
-
SR on Node 2 looks up the location of the entity and forwards the message via the Akka Cluster to the SR running on Node 3
-
The SR on Node 3 knows entity ID=6 and forwards the message for processing by that entity
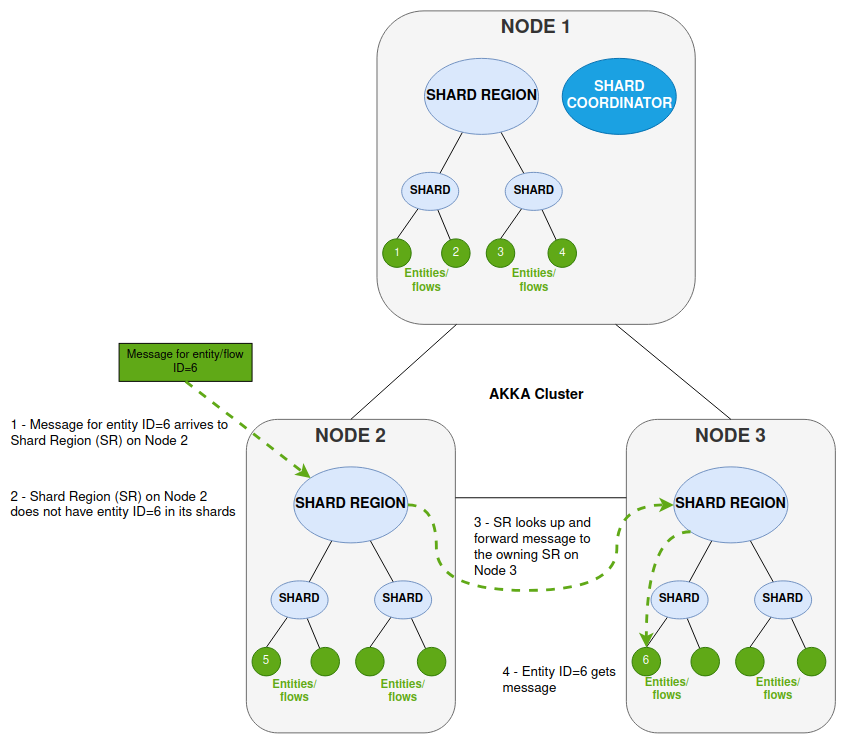
The real scenario for this from an IPF processing perspective is where you have multiple nodes processing from the same Kafka topics.
-
Where the IPF flow sends a request to an external domain, the node which processes the response is not controlled at the Kafka level.
-
Each node will read responses from the same Kafka topic but the node reading the response might not have been the node processing the request (& hence the location of the flow entity)
This is Location Transparency, and means that for BAU processing the cluster handles the routing to a physical location, and we can simply refer to the entity by its logical ID. This is how IPF works to route the messages to the correct IPF flow instance. And this is crucial not just from a BAU perspective but also, from a resiliency and failure scenario perspective, to cope with node failure and restart.
Note the introduction of a Shard Coordinator. This has a number of responsibilities and is crucial to allow that routing and location transparency. Shards are managed by the Shard Coordinator (SC) and it:
-
is a cluster singleton (there is only ever 1 within an Akka Cluster)
-
monitors system nodes and location of each shard
-
ensures the system knows where to send messages for a specific entity
-
decides which shard lives in which shard region
-
Is backed by Akka persistence – to replay events on failure of the SC to allow it to resume its state.
Node Down Scenario
The following shows what happens in the Akka Cluster when a node fails or is restarted. The functionality and behaviour here ensures entities can be resumed on other nodes and processing can continue BAU regardless of the node failure.
Two things are happening in this scenario where some infrastructure is down making a Shard Region (SR) unavailable.
-
Node 2 receives the message which is for entity/flow ID=6
-
The Shard Region (SR) on Node 2 does not have that entity within any of its shards (entity ID=6 is not running on Node 2)
-
The SR receiving the message tries to send it to the SR having the entity (this was on Node 3)
-
But the SR on Node 3 is now unavailable
-
-
The Shard Coordinator steps in to move the Shard to a different SR (in our case Node 1)
-
SR on Node 2 now forwards the message via the Akka Cluster to the SR running on Node 1
-
The SR on Node 1 knows entity ID=6 (its Shard was just moved here) and forwards the message for processing by that entity
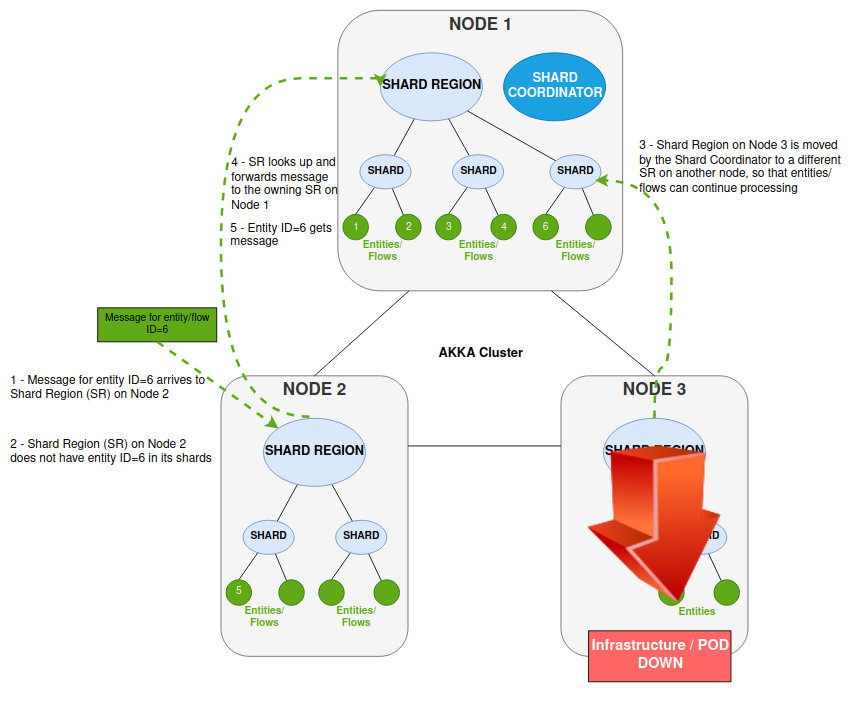
The most important things to note in this scenario are that the location of the running flow (entity) is transparent, and it is the Akka Cluster that provides the routing to the correct shard and hence node. Each entity runs in only one place and thus those running entities can be distributed and moved around the cluster without any sender having to know the location/node of the destination actor. The entities are persistent and thus can be resumed in any shard on any node, since it will replay the events to resume the correct state.
Network Partitions / Split Brain Resolution
By default, we implement the default method of split-brain resolution of keep-majority in IPF provided by Akka, this allows for the best blend of scalability in a cloud environment.
| Strategy | Requirements |
|---|---|
keep-majority (default) |
Odd number of nodes in overall Akka Cluster |
lease-majority |
Must only be a single Kubernetes cluster |
keep-oldest |
Could lead to the largest quorum being terminated |
If a client is running in an environment where only two Data Centres are available, and each data centre has its own isolated Kubernetes cluster, then keep-oldest caters for scenarios in which a single DC (half of nodes) become partitioned and uses the cluster singleton to act in arbitration for cluster health.
Common Questions
Q. How does the Shard Region (SR) know what entities/flow instances it has?
The SR keeps track of all the shards and entities it has. This means it doesn’t need to resolve the location externally (with the Shard Coordinator) every time.
Q. If the shard is in another SR how does it get the message to the correct SR (& hence node)?
If the shard is in another SR then messages must be forwarded to that SR instead. The SR receiving the message has to resolve the location of the target shard from the cluster, and the Shard Coordinator (SC) is responsible for knowing the location of all shards and entities across the whole cluster. Once the location is resolved the messages are delivered to the target shard.
Q. Whilst the SR is resolving the location of a shard, what happens to incoming messages for that entity?
While resolving the location of the shard, incoming messages are buffered and will later be delivered once the shard location is known. Any subsequent messages resolved to that 'remote' shard can be delivered to the target destination immediately without involving the shard coordinator to determine the location.
Q. How do we ensure no state is lost moving entities/flows between SR?
We use Akka persistence to store the events, and allow the state of an actor to be recovered by replaying events on entity/flow restart.
| the shard coordinator is also backed by Akka persistence – to replay events on failure to allow it to resume its state. |
Q. If one node sends a request to an external domain (e.g. Sanctions) but its response is read from Kafka by a different node, how does the right flow get that response?
This is the scenario described above in "BAU Cluster Operation" and is the normal operation since we want Location Transparency for the entity (meaning it can be moved or recovered as necessary).
Q. If a node goes down what happens to the entities/flows processing on the shard region for that node?
This is the scenario described above in "Node down scenario" and covers how shards with their entities are moved to run within another shard region.
Q. What is shard rebalancing?
This is the process by which the shard coordinator facilitates rebalancing of shards, where new members are added to the cluster. Thus, entities can be moved from one node to another. The process of rebalancing will cause shard regions to buffer incoming messages for a shard and the coordinator will not respond to location requests until the rebalance in completed. Those entity messages are thus buffered until the coordinator responses to location requests, at which point routing of those buffered messages can resume.
Q. What happens if the shard coordinator goes down?
The state of the shard coordinator is persistent and so can be recovered. If the coordinator crashes or the node becomes unreachable a new shard coordinator singleton will take over and state is recovered from the persistent store. During this time any known locations are still available to the shard regions but any requests for locations are buffered until the coordinator is back online.