Frequently Asked Questions
This section provides answers to commonly asked questions, split down into several sections. You can use the search bar to search the whole site, but these FAQs should link to associated documentation within the developer docs.
| This is a living document and questions are being added as they become obvious. |
General
What is IPF?
IPF - Icon Payments Framework. It is a low code framework that enables banks to develop their own payment processing solution by leveraging the IPF SDK and any desired optional modules or ready-made scheme packs.
Is IPF cloud native?
IPF is Cloud Agnostic (i.e. not relying on a specific cloud platform), but not cloud native.
What is an AOM?
Additional Optional Modules (AOM) provide supporting functionality that are subject to an additional license on top of the IPF Core license.
Some examples are
-
Identity resolution
-
Operational Data Store (ODS)
-
Scheme Packs
For the complete list and more details, please see AOM
Does IPF support ISO20022?
Yes, internal data models used in IPF components and applications are based on ISO20022 message types.
Are there scheduled maintenance windows in payment solutions built using IPF?
None of the IPF components, applications or solutions built with IPF require maintenance windows by default. They are built in such a way to support rolling upgrades with built-in backward compatibility support where possible.
Maintenance windows are generally required due to the bank’s environment/infrastructure requirements or bank systems requiring such maintenance. Payment solutions built with IPF are required to support the unavailability of those dependant systems by managing processing of in-flight/new payments in a graceful way.
Can processing applications built with IPF support multiple bank legal entities?
Yes, payment solutions built with IPF and the supporting IPF applications support multi-legal entity solutions. Payment processing and payment data views are logically segregated by processing entity which is an identifier for a legal entity.
How can I learn IPF?
The tutorials are a great place to start - learn::home.adoc
How to identify a single transaction?
IPF uses a unique reference (unitOfWorkId) for all transactions processed, and can ensure that customer-provided references are correlated to IPF internal references in order to facilitate successful reconciliation and provide traceability.
Is IPF only for instant payments?
No, both instant and non-instant payment solutions can be built using IPF. The SDK can also be used to build other payments processing solutions internal to a financial institution.
Is IPF only for single individual payments?
No, solutions built with IPF can process payments initiated individually, in bulk, immediate or future dated. IPF also supports business days processing as well as 24/7 and clearing windows supported by the respective CSM service.
Does IPF support bespoke payment validation?
Yes, IPF not only provides a set of technical and business payment validations, it is also possible for the banks to code custom business validations to be called from IPF processing flows. Underlying process steps in flows can be integrated with a pre-existing system to perform payment validations.
Does IPF provide a user interface?
IPF has delivered a GUI (Operational Dashboard) that provides the ability to search payments/transactions, view payment summary/details, payment execution history, runtime execution graph, raw messages exchanged for a payment and more. It doesn’t manage users but it supports single sign on by integrating with the bank’s IAM via OAUTH or SAML. It also supports mapping the GUI roles to the bank specific roles. In addition to payment transaction data, it also makes API calls to various IPF applications to fetch and update dynamic settings and data.
IPF Operational Dashboard is based on IPF GUI framework, therefore it’s extensible. Clients can add their bank specific modules (screens and API integrations) using the IPF GUI framework features and create their own customised/extend Operational Dashboards.
Does IPF provide a user interface to manage payment returns, recall/reversal?
IPF provides a set of API definitions for returns, recalls and ROIs. For API definitions see IPF APIs
The implementation of such APIs is subject to bank specific requirements and can easily be defined as processing flows within an IPF orchestration. Flows can be defined in MPS using Payments DSL and bank specific system integration can be achieved with the use of IPF connector and mapping frameworks.
What is a processing entity?
This is the entity for which a payment is processed. This can be:
-
an internal debtor/creditor account servicing entity that has its own CSM agent relationships and/or use another internal entity to route, clear and settle payments
-
an external entity that makes use of an internal entity to route, clear and settle payments
-
an internal entity that routes, clears and settles payments for other internal and/or external entities (which operate as indirect CSM participants)
What is Payments DSL?
Also referred as Flo-lang.
Orchestration is one of the key areas where IPF sets itself apart. We have built our own unique payments domain specific language (DSL) leveraging JetBrains MPS which enables clients to build solutions using the DSL with minimal dependency on Icon. See Orchestration Framework and learn:tutorials:dsl_intro.adoc
Does IPF provide a business workflow/process modeller?
Yes, we have built our own unique, low code Domain Specific Language (DSL) leveraging JetBrains MPS. It can be used by business and technical users alike to define customised payment processing flows without being dependent on a vendor.
Using Payments DSL, a bank will be able to define their own payment processing flows based on their requirements. Using Payments DSL provides clear orchestration capabilities and provides direct use of an ISO20022 based canonical data model support for payments.
When defining their orchestration flows, clients are able add required data models from IPF canonical data library. Client specific data models where required can be imported, meaning client specific data could become the part of processing as well as the generic IPF canonical data models.
The flow is made up of states and events, where events provide the trigger to move between states.
The SDK and DSL provide a number of features and functionality:
-
Automated generation of the flow source code
-
Automated generation of BDD testing scripts, graphical views and supporting documentation
-
Process forking based on customisable conditions
-
Interoperability with existing, bank as well as 3rd party, applications
-
Parallel orchestration
-
Pre-built ISO20022 type data library
-
Retry, Timeout and Exception handling
-
Ability to define sub-flows that are reusable within a single flow and across multiple flows
-
Version control
For more details on this, Orchestration Framework
How do I define flows using IPF?
Using the MPS JetBrains Editor and the IPF Payments DSL. Try it out learn::home.adoc
What is a domain event?
A domain event is a critical fact, the event meaning something specific has happened which may cause some change to the processing of our payment. Domain events help you to express, explicitly the domain rules and are based in the ubiquitous language provided by the domain experts.
In IPF orchestrations, domain events are critical parts of payment processing, explicitly declared. They are only published if they are recorded. They are immutable. They are used to load the current state of an aggregate (transaction) by replying recorded domain events without side effects. They also provide the execution history - "what happened to my transaction information?"
What is a system event?
IPF System events occur when something has happened to the system and tend to be quite granular. They can be used to notify consumers of various events that take place in the IPF ecosystem (or any system related to internal processing of IPF components and applications). These can be converted to meaningful statistics, reformatted and relayed to other downstream systems for consumption and subsequent action. It is also possible to define bank specific systems events, especially used within bank implementations. See IPF System Events for more info.
How can I view system events?
System events can be logged into a log file or published into a Kafka topic, and this is configurable via application config. See IPF System Events for more info.
As a bank can I define my own system events if not available in the default catalogue?
Yes, bank specific system events can be defined following the IPF system events framework and the event structure. Bank system events will be defined within the bank specific IPF implementations. For more info on how to do this, please see Define Events
How can I know what happened to my payment?
IPF provides many features to support tracking, monitoring and archiving of payments or related transaction data.
Archiving: IPF can provide the aggregated payment data and processing information in IPF canonical format published to a kafka topic (default) so that bank can consume from and transform/push the information to its archiving system.
Domain events: Payment solutions built with IPF, can publish domain events (recorded facts about a payment during processing, e.g. SanctionsCheckPassed) into a centralised Kafka topic. This approach enables the bank to react fast to any critical payment domain event and for example send alerts to a bank operator.
Raw Message Logging: Any messages exchanged during a payment process can be published into a centralised Kafka topic and also recorded in IPF ODS (Operational Data Store). These messages can either be consumed and published into bank’s centralised auditing solution or can be feed to ODS and accessed via ODS APIs. These can also be displayed via IPF Operational Dashboard screens as part of payments detailed view.
Payment Data and Tracking: The IPF ODS via APIs (or IPF Operational Dashboards) provides payment search, payment summary view, detailed payment view and for each payment an execution history which is composed of domain events recorded for that payment during processing, runtime execution graph of a payment, raw messages exchanged for a payment. See aom:ods:home.adoc for more info on ODS.
System Events: IPF System events can be used to notify consumers of various events that take place in the IPF ecosystem (or any system related to IPF). These can be converted to meaningful statistics or reformatted and relayed to other downstream systems for consumption and subsequent action. See here for the default catalogue of system IPF System Events.
Payment solutions built using IPF also benefit from the ability to create bank specific system events in addition to the default list. System events by default can be exported to log files. These log files can be aggregated using a data gathering application (e.g. Splunk, ELK, etc.) and used for further monitoring.
Metrics : IPF core components provide a default list of useful IPF technical and business metrics which help monitor the solution. For the default list of connector and application metrics see: Metrics.
These metrics are in addition to the default JVM metrics and also metrics provided by the Akka framework which is the underlying technology of IPF core. In the background IPF uses Lightbend telemetry which, in turn, uses Open Telemetry API to export metrics into a number of backends. IPF by default exposes these metrics via Prometheus, meaning metrics are exported using Prometheus exporters and displayed in Grafana Dashboards, see Time Series Metrics.
Logging: IPF uses Logback for logging configuration. This allows the user to configure a logging setup which can mirror that of other applications developed inside the organisation. See Logging.
Is it possible to see what raw messages exchanged for a payment?
Yes
Messages exchanged for a payment are stored as part of message logging. As part of the connector framework, when defining a connector, message logging can be implemented specifically for a banks implementation requirements.
Messages can be published into a centralised processing-data topic. ODS ingestion, for example consumes from this topic and stores the messages. Thia data is queryable and ODS exposes APIs to retrieve messages for a given payment. Additionally, IPF Operational Dashboard has a tab in payment detail view that lists all the messages exchanged for the selected payment, achieved by querying ODS Inquiry API.
Integration - Connector Framework
Will any outgoing message be stored in IPF?
Yes - see question - Is it possible to see what raw messages exchanged for a payment?
What are the options to integrate a solution built with IPF to other bank systems?
IPF supports a variety of integration mechanisms and protocols thanks to its Connector Framework which is a standardised framework for defining connectors (integrations) with external/bank systems. This supports both sync and async integrations as well as the majority of connectivity protocols (MQ, Kafka, HTTP etc.) providing highly resilient integrations. IPF Connector Framework supports auto-recovery mechanisms such as configurable retries, backpressure, throttling and more. See Connector Framework for more information.
Additionally IPF Operational Dashboard supports integrating with bank’s IAM via OAUTH/SAML in order to provide single sign on capability. IPF GUI framework which provides ability to build bank specific UI screens provides OAUTH/SAML/LDAP integration with bank’s IAM so that any UI built using IPF GUI Framework easily supports single sign on.
What integration points does IPF provide?
As part of the SDK IPF offers customisable orchestration and integration approach, supported by it’s connector (Connector Framework) and mapping (IPF Mapping Framework) frameworks. Meaning that the bank does not integrate with IPF, rather it uses IPF to define and build payment processing applications that integrate with the bank and 3rd party applications either synchronously or asynchronously. It does this using common data interchange formats (such as XML or JSON) and a multitude of transports (such as HTTP, JMS, MQ, Kafka, etc).
In addition, there are also a set of out of the box supporting applications offered by IPF for payments solutions. These applications provide reusable business functions to be called from process flows, in the form of APIs. Integration with these applications is generally a combination of HTTP or Kafka/messaging APIs, in json format.
Additional Optional Modules (AOM)
What is a Scheme Pack?
Also known as CSM Service, it is a microservice that enforces a given Clearing and Settlement Mechanism (CSM) rulebook. This includes connectivity and data model to format the messages to be sent and received from a given clearing & settlement mechanism e.g. RT1, STET, STEP2.
What is the CSM Reachability Service?
An IPF application that is responsible for providing participant reachability information. It also provides various useful business functions via its APIs such as get reachable CSMs, deconstruct IBAN, validate BIC, select CSM agent as well as settings management APIs.
What is the Identity Resolution Service?
IPF comes with an Additional Optional Module (AOM) called Identity Resolution Service, which leverages 3rd party technology from the company NetOwl.
As part of this module, the solution is able to take the name and address that is present in the payment message and compare it against the name and address held in the customer information system at the bank. The service will return a score (which is calculated based on complex language algorithms) which is interpreted by the flow based on configurable thresholds to determine the next step. For example, if the score is below 0.6 then that could mean the payment is rejected or sent for manual intervention.
What is the Payment Status Notification Service?
Payment Status Notification service is an application provided as part of IPF core and provides Pain002 type payment status notifications for the payments being processed in an IPF payment processing solution.
Bank channels are typically interested in payment status notifications but they don’t want to be spammed with every little payment status change. Pain002 notifications published by the Payment Status Notification service are more major changes. The definition of what a major status change is configurable based on a filter.
Payment Status Notification service is responsible for consuming domain events from the ipf-processing-data Kafka topic and based on a configurable filter publishing Pain002 notifications in Json format to another Kafka topic for the bank systems to consume.
What is the ODS?
The IPF Operational Data Store (ODS) is IPF’s answer to enable data views across its processing. It provides a unified, and eventually consistent insight into the end-to-end lifecycle of a payment. This will be the result of execution of multiple processes, such as initiation, execution, clearing and settling, cancellation. It will also include integration with other bank systems, such as fraud and sanctions checks. aom:ods/home.adoc
What is the Human Task Manager Service?
An IPF application that provides an easy and simple way to manage human tasks that are registered by processing flows. Some examples of such tasks could be to approve or repair a payment.
Human Task Manager provides APIs to search/list, view task details, claim/unclaim, approve/reject and capture the execution result of tasks. The detailed task screens and capturing task result screens are bank specific.
Business Functions
Does IPF Perform technical and functional duplicate checking?
These 2 validations are achieved via the use of a Transaction Cache (core:flo-starter:features/tx-cache.html), used in the implementation to perform the comparison of hashed fields that need to be specified in accordance to customer requirements.
What is Dynamic Processing Data?
A dynamic processing setting (DPS) is an IPF term for dynamically changeable configuration that is used during processing of a payment/transaction so that the update is applied instantly or scheduled to be applied, but overall doesn’t require application restart to take effect.
For a setting to be implemented as a DPS it must make sense from a payment/transaction flow perspective.
In order to update a dynamic setting, an approval process may be required, based on a "requires approval" flag. This gives higher flexibility on updating a setting, as not all updates may require approval.
Some examples of the applications that are using DPS are:
-
CSM Reachability Service
-
CSM agents, participants, processing entity are a few examples of data that has been implemented as DPS.
-
-
Working Day Service
-
Calendar data is another example of DPS. Calendar data types are defined as settings catalogue and DPS is embedded within the working day service application as a supporting feature.
-
Operational Data Store (ODS)
What is the ODS?
See What is the ODS?
What are the main features provided by ODS?
ODS Ingestion: consumes IPF Processing Data from Kafka, transforms it into the ODS data model and persists. Some of this ODS data is published to a payment summary actor, which enriches the data in turn to create/update a persisted summary view.
ODS Inquiry API: provides APIs to list payments, view payment details, view execution history (domain events) for a payment, view runtime graph representation of the processing flow for a payment run, view list of raw messages exchanged for a payment.
It is also possible to store and view system events within ODS as well, however for higher volumes, it is recommended to export system events into log files and display via log aggregation tool such as Splunk, rather than using ODS.
These API’s are used by IPF Operational Dashboard to present the data in the form of Operational and auditing dashboards but can also be used to extract the information into external systems such as Pega, etc.
Is it possible to create downstream feeds for other bank applications or data store?
Processing applications that are built with IPF orchestration record domain events as important facts related to a payment and can be configured to publish them into a centralised Kafka topic : ipf-processing-data. The data from this topic can be consumed by a client built application to feed practically any other bank system as required.
ODS ingestion provided by IPF, consumes the domain events from this topic and transforms the domain event data into queryable views in the read side database. In the same way another application can consume from the same ipf-processing-data topic and provide downstream feeds as required.
Additionally, ODS inquiry provides payments data via ODS APIs from the queryable views. These APIs can be used and called to provide required downstream data.
What is the maximum number of transactions exportable from the ODS search?
It’s the value of the maximum search set size configured to be in ODS. The default is 1000.
Monitoring & Alerting
What is the IPF offering regarding Business Alerting and Monitoring?
IPF exposes system events and also Prometheus metrics (following the Open Telemetry standard). These can be used to extract metrics, benchmarking and display on dashboards using Grafana.
System events can be exported into log files. It is then possible to use a log aggregation tool (e.g Splunk) and view all system events published by IPF applications
Does IPF provide default set of metrics?
IPF core components provide a default list of very useful IPF specific technical and business metrics which help monitor the solution. For the default list of connector and application metrics see: Metrics.
These metrics are in addition to the default JVM metrics and also metrics provided by the Akka framework which is the underlying technology of IPF core. In the background IPF uses Lightbend telemetry and supports exporting metrics into a number of backends.
IPF by default exposes these metrics via Prometheus, meaning metrics are exported using Prometheus exporters and displayed in Grafana Dashboards. IPF Operational Dashboard also supports displaying Grafana dashboards as widgets as part of the UI screens.
What is message logging?
In many applications there are often requirements around keeping a record of every message. This could be for monitoring, auditing, or data warehousing purposes. Regardless of the use case, the connector library provides an optional message logging facility that will publish both sent and received messages.
What are logging options IPF supports?
IPF uses Logback for logging configuration. This allows the user to configure a logging setup which can mirror that of other applications developed inside the organisation, and make IPF report log data in the same way. See Logging.
Resilience
How do solutions built with IPF cope with expected and unexpected failures?
IPF orchestration and the connector framework provides a variety of mechanisms to cope with expected and unexpected failures. Some examples of these mechanism are:
-
Applying backpressure when a bank system is slow in responding. This means, if configured, the payment solution will buffer or slow down consuming new payment requests if a downstream bank system is responding slowly.
-
Configurable throttling: It’s possible to configure throttling for each connector.
-
Stop/start consuming new messages: Each connector is able to receive instruction to stop/start consuming new messages.
-
Retry with exponential backoff for max number of times: It’s possible to configure connectors with retry properties. Processing flows defined using IPF orchestration also support action timeout, retry and action revival configurations in order to support auto-recovery from failures.
Performance & Scalability
What response times can be expected and are usual for solutions built using IPF? Do you have some benchmarks?
The latency for a payment to be processed within a payment solution built with IPF mainly depends on:
-
network latency between local datacenters and the private cloud provider,
-
network latency within the AZs of the cloud provider and also
-
number of integrations of the flow with bank systems
-
latency/response times of the bank systems
-
complexity of the flow
IPF core components are designed and engineered to support high throughput low latency applications with built-in resiliency capabilities.
In our internal tests done with a hypothetical bank implementation (sample-client), using simulators for bank systems and the CSM, with the correct scaling and configuration we are able to achieve for an end-to-end transaction latency under 2s within the 99th percentile
How can a solution built with IPF be scaled to changing load or performance needs? What would be the impact on the underlying infrastructure ?
IPF has been architected from the ground up to be scalable. IPF solutions can be deployed in active-active fashion across multiple datacenters.
The Akka Actor framework allows functional components to communicate transparently with other components, whether the components are located on the same host or other hosts within the same data centre or across data centres.
Vertical Scaling Deployment of the solutions using IPF requires capacity planning and sizing of the host servers with consideration of:
-
Bank-specific guidelines, best practices and acceptance criteria
-
Bank-specific non-functional requirements
-
Initial payment volumes and growth forecasts.
Horizontal Scaling Horizontal scaling of IPF within that context is achieved by deploying:
-
Containers (the run-time context for IPF) across multiple hosts/servers within and across data centres
-
Kubernetes or similar container management tool configuration rules specify the container distribution rules across hosts.
In order to support the maximum availability it’s recommended to deploy IPF solutions on to n+n+1 AZs/datacenters.
Deployment
Are there any specific environment requirements that a bank would need to meet to host solutions built with IPF?
Applications/solutions built with IPF generally require the following as minimum for deployment:
-
MongoDB Enterprise 4.2 or greater
-
Kafka
-
Java 11 (moving to Java 17 from IPF release V2024.1 (May 2024))
The preferred approach to run applications is using containers in Kubernetes. However, it’s also possible to run on VMs and Openshift locally.
What are the hosting options available for IPF solutions?
Icon will provide the IPF software (in the form of an SDK) which an SI partner or bank will use to implement the required solution in the bank’s own environment and hosted by the bank.
IPF based payment processing applications are cloud-agnostic and currently proven on AWS. It’s also possible to deploy solutions built with IPF on-premise.
Containerisation in IPF is by default in Kubernetes, deploying Docker containers, however Openshift is also supported.
Does IPF support Rolling Upgrades?
Applications built with IPF are designed to support zero downtime rolling upgrades.
However this is also subject to bank specific implementations and customisations introduced by the bank.
Development
What are the tools and technologies required to start developing application using IPF?
-
Maven - version 3.8.4 or higher (Maven)
-
MPS/ Flo-designer - version 2021.3 (MPS) for defining orchestration/process flows
-
Intellij (or other IDE) (IntelliJ)
-
Java 11 (JDK11) (moving to Java 17 from IPF release V2024.1 (May 2024))
Also see learn:tutorials:home.adoc
What version of Java is IPF using/supporting?
From release V2024.1 (May 2024), IPF uses Java 17/Spring 6/Spring Boot 3 for all IPF components (all IPF versions prior to this are using Java 11). You will need to use Java 17 at design, build and run time.
Java 17 was chosen based on trying to balance the support of a more recent LTS version of Java and our clients ability to support/run that version.
What is the technology stack IPF is based on?
IPF is built on top of a well known, widely used technology stack which means that documentation for each of the technologies used is largely available online:
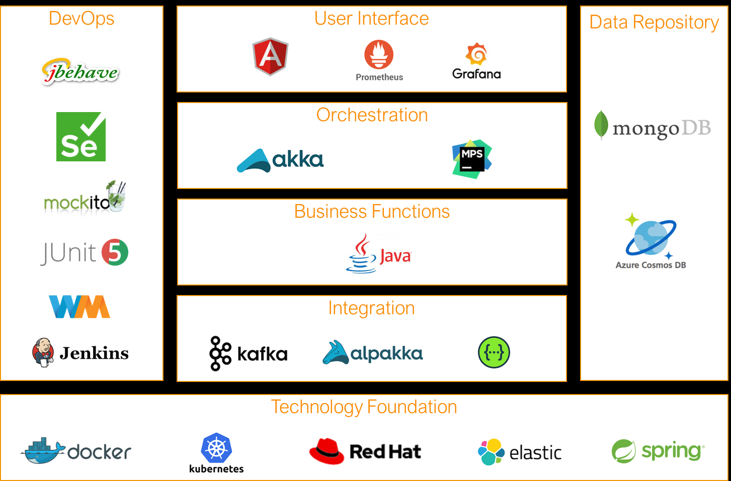
-
DevOPs
-
User Interface
-
Orchestration
-
Integration
-
Data Repository
-
Technology Foundation
What documentation exists for IPF?
IPF provides rich documentation and tutorials to enable effective self-service learning which complements the instructor-led and hands-on training.
IPF documents are living documents and they are maintained within the same repo as the code. Therefore for any release updates the respective documentation is updated consistently.
IPF developer docs are available on this site - docs.ipfdev.co.uk/
IPF also provides flow document generation for solutions. Flow definition is done in MPS using Payments DSL. During the build process, IPF generates the flow documentation, graphical representation of the flow and the test scenarios in BDD form. All this output can then be used as part of the bank specific implementation documents, eliminating the manual documentation for the orchestration.
Security
Is IPF code base checked against known vulnerabilities?
Yes, IPF code base is periodically checked in our internal code scans as part of our CI/CD pipeline to identify any vulnerabilities:
-
Code Quality and security – SonarQube
-
Open Source Vulnerabilities (Security and License) – Sonatype Nexus IQ
How is data at rest protected and which encryption options are available?
IPF uses MongoDB database which has it’s own mechanisms for securing data (Resource: MongoDB Security), we encourage usage of MongoDB encryption mechanisms since no additional encryption is utilised on IPF side.
To encrypt data at rest, MongoDB Enterprise offers native storage-based file symmetric key encryption, which means that users can use transparent data encryption (TDE) to encrypt whole database files at the storage level. First offered in version 3.2, MongoDB utilises the Advanced Encryption Standard (AES) 256-bit encryption algorithm, an encryption cipher which uses the same secret key to encrypt and decrypt data. Encryption can is turned on using the FIPS mode thus ensuring the encryption meets the highest standard and compliance.
The whole database files are encrypted using the Transparent data encryption (TDE) at the storage level. Whenever a file is encrypted, a unique private encryption key is generated and is good to understand how these keys are managed and stored. All the database keys generated are thereafter encrypted with a master key. The difference between the database keys and the master key is that the database keys can be stored alongside the encrypted data itself but for the master key, MongoDB advises it to be stored in a different server from the encrypted data such as third-party enterprise key management solutions.
For more information on how to configure encryption of data at rest please refer to official MongoDB documentation (Resource: Encryption at Rest).
While encryption improves security, the downside is that it introduces some performance impacts, which are described in following article (Resource: Data-At-Rest Encryption - Features and Performance).