Cómo implementar un desmoldeo básico
Para completar esta guía, usted necesitará lo siguiente:
-
Para conocer su versión actual de IPF
-
Para conocer el IPF apropiado Scaffolder Versión
Creando el proyecto
Comenzaremos creando un nuevo proyecto como cualquier otro.
mvn com.iconsolutions.ipf.build:ipf-project-scaffolder-maven:<your-scaffold-version>:scaffold \
-DgroupId=com.icon.ipf \
-DartifactId=debulk-example-1 \
-DsolutionName=DebulkSolution \
-DprojectName=DebulkProject \
-DmodelName=DebulkModel \
-DincludeApplication=y \
-DflowName=BulkFlow \
-DipfVersion=<your-ipf-version> \
-DoutputDir=/build/debulk-example-1Una vez construido, construiremos el proyecto.
mvn clean install -DskipTestsEstructuraremos nuestro ejemplo de debulker utilizando un pain001 estándar como nuestra entrada. Lo trataremos como un conjunto de cuatro flujos:
-
Un flujo de 'Archivo' para representar el manejo del archivo que llega.
-
A 'Bulk flujo para representar el sobre de nivel superior del pain001 en sí mismo.
-
Un flujo de 'Batch' para representar la parte de instrucción del pain001.
-
Un flujo de 'Transacción' para representar la parte de transacción del pain001.
Ahora abramos el proyecto en MPS. Veremos que nuestro 'Flujo de Archivos' ya ha sido proporcionado para usted.
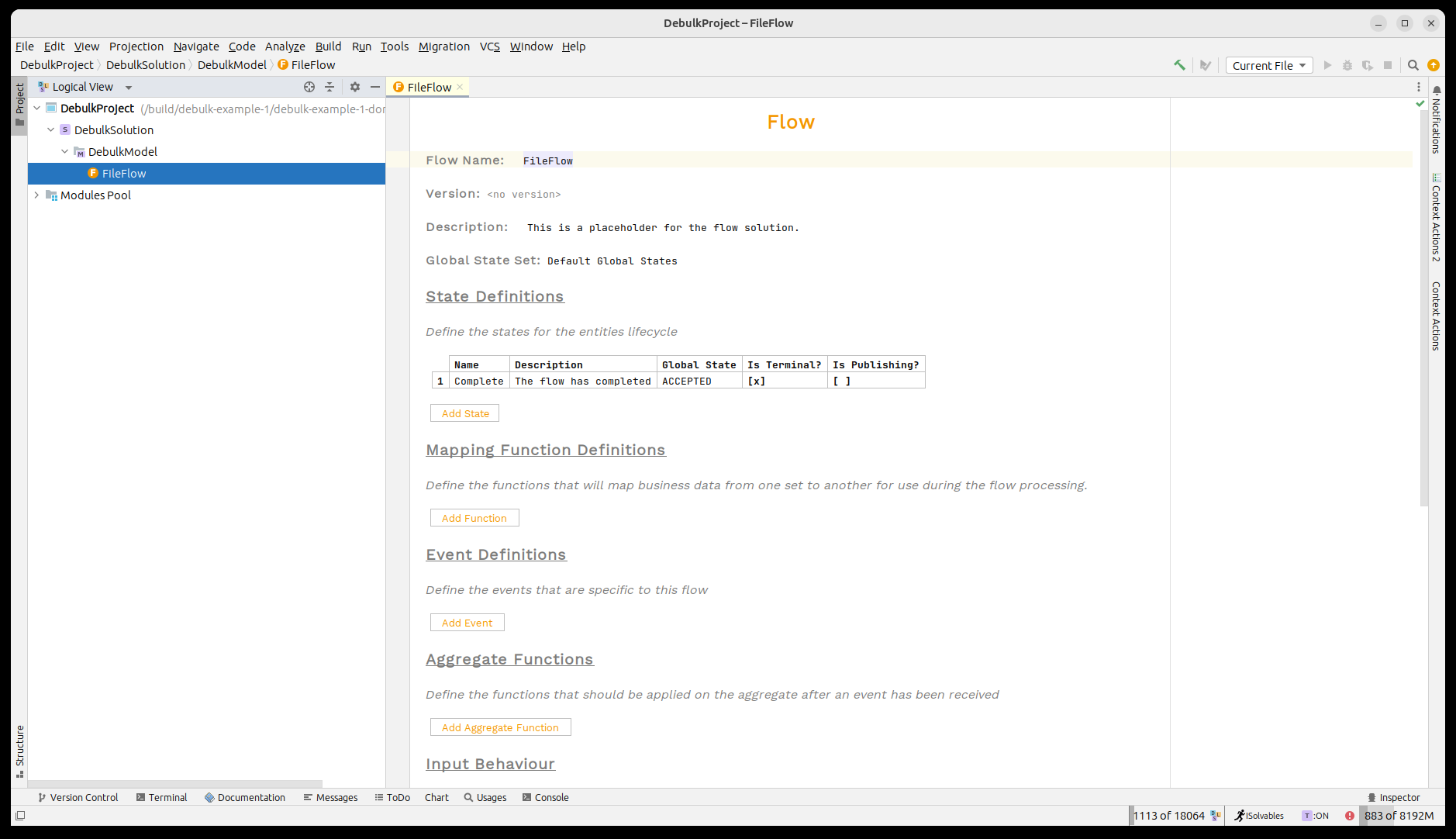
Un breve recordatorio sobre el IPF Component Store
El almacén de componentes IPF se utiliza para descomponer archivos grandes en componentes que luego pueden ser utilizados dentro del sistema flo normal. En nuestro caso, vamos a utilizar archivos pain001 y dividirlos en los diferentes niveles del archivo.
El almacén de componentes requiere la configuración para indicarle cómo dividir cualquier estructura de archivo que reciba. Esta configuración se proporciona en forma de hocon; en el caso de pain001, se presenta un ejemplo a continuación:
ipf.debulker {
archiving.path = "/tmp/bulk_archive"
configurations = [
{
name = "pain.001.001.09"
splitter = "xml"
processing-entity = "BANK_ENTITY_1"
archive-path = "/tmp/bulk_archive"
component-hierarchy {
marker = "Document"
children = [
{
marker = "CstmrCdtTrfInitn.PmtInf"
children = [
{
marker = "CdtTrfTxInf"
}
]
}
]
}
}
]
}Los puntos clave a tener en cuenta son:
-
El nombre 'pain.001.001.09' cuando se recibe una instrucción para procesar un archivo, este nombre debe ser proporcionado para indicar al almacén de componentes que utilice esta configuración.
-
Cada nivel de 'marcador' representa los diferentes niveles de nuestro pain001 como se describió anteriormente.
Modelando el Proceso
Creando el 'Bulk' flujo
El flujo a granel será responsable de recibir algún tipo de instrucción que incluya detalles sobre dónde se almacena el archivo pain001. Luego, interactuará con el almacén del componente IPF para leer el archivo y descomponerlo en el componente apropiado antes de iniciar el procesamiento de los flujos de nivel superior.
Desde el punto de vista de las instrucciones, el almacén de componentes necesita que se proporcione la siguiente información clave:
-
Un ID único para el debulk-esto está modelado por el elemento de datos 'Debulk ID'.
-
El nombre de la configuración a utilizar-esto está modelado por el elemento de datos 'Debulk Config Name'.
-
La ubicación del archivo de datos-esto está modelado por el elemento 'Debulk Source'.
Comencemos añadiendo esos tres elementos de datos como datos de iniciación en nuestro flujo. Para ello, primero necesitamos importar la biblioteca de datos comerciales de debulker. Esto se puede hacer presionando CTRL+R dos veces y luego buscando 'IPF Debulker Business Data.
Una vez completado, deberíamos lucir como:
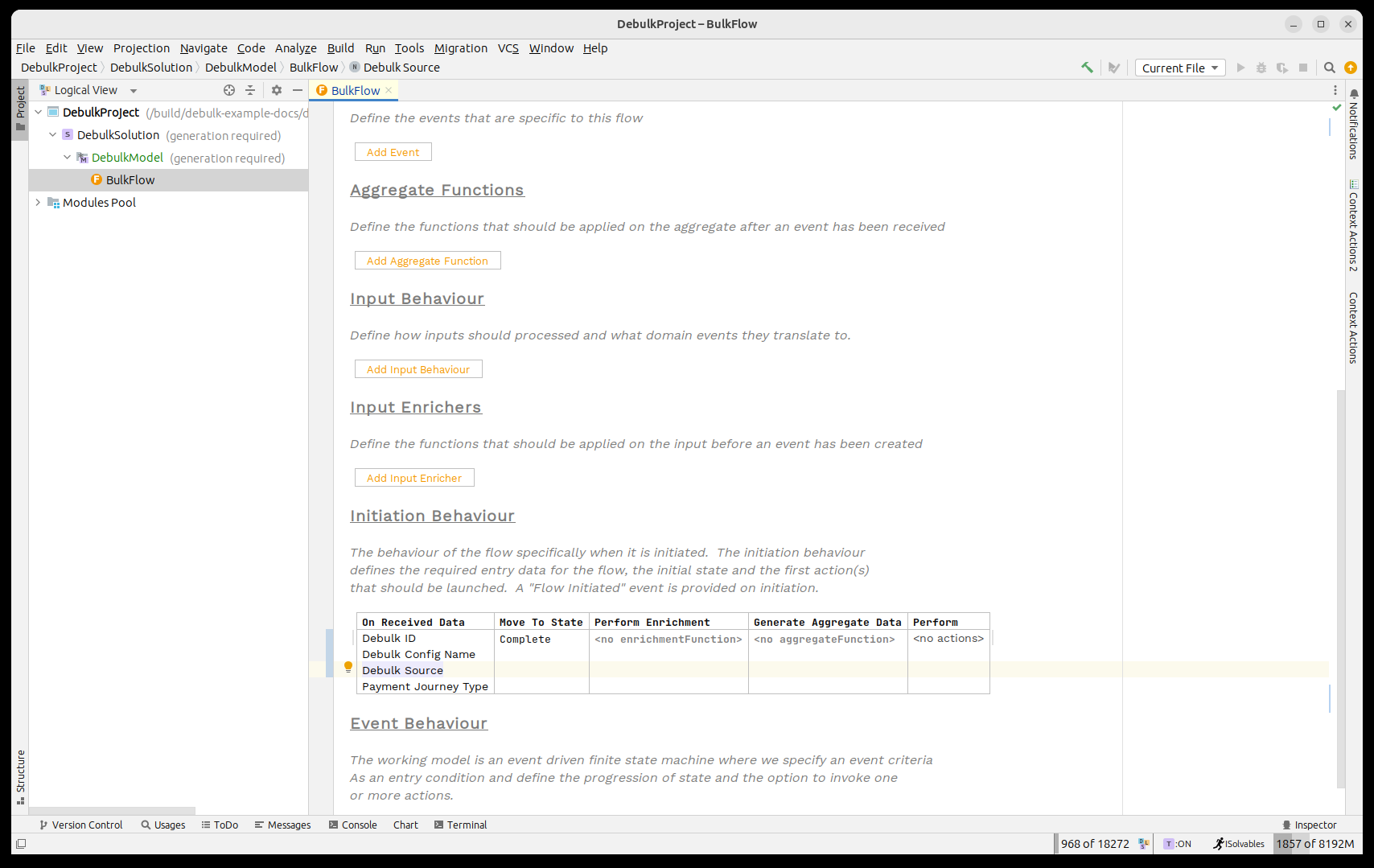
| Aquí estamos utilizando los puntos de datos directamente, pero es perfectamente razonable absorber su propio tipo de archivo y luego utilizar una función de agregación para extraer los campos IPF requeridos. |
A continuación, necesitamos invocar el 'IPF Component Store' para procesar el archivo masivo. El almacén de componentes ha sido modelado como el 'IPF Debulker Dominio'. Esto tiene una función disponible 'Iniciar Debulk' que toma los tres campos que hemos puesto a disposición y procesará el archivo como resultado.
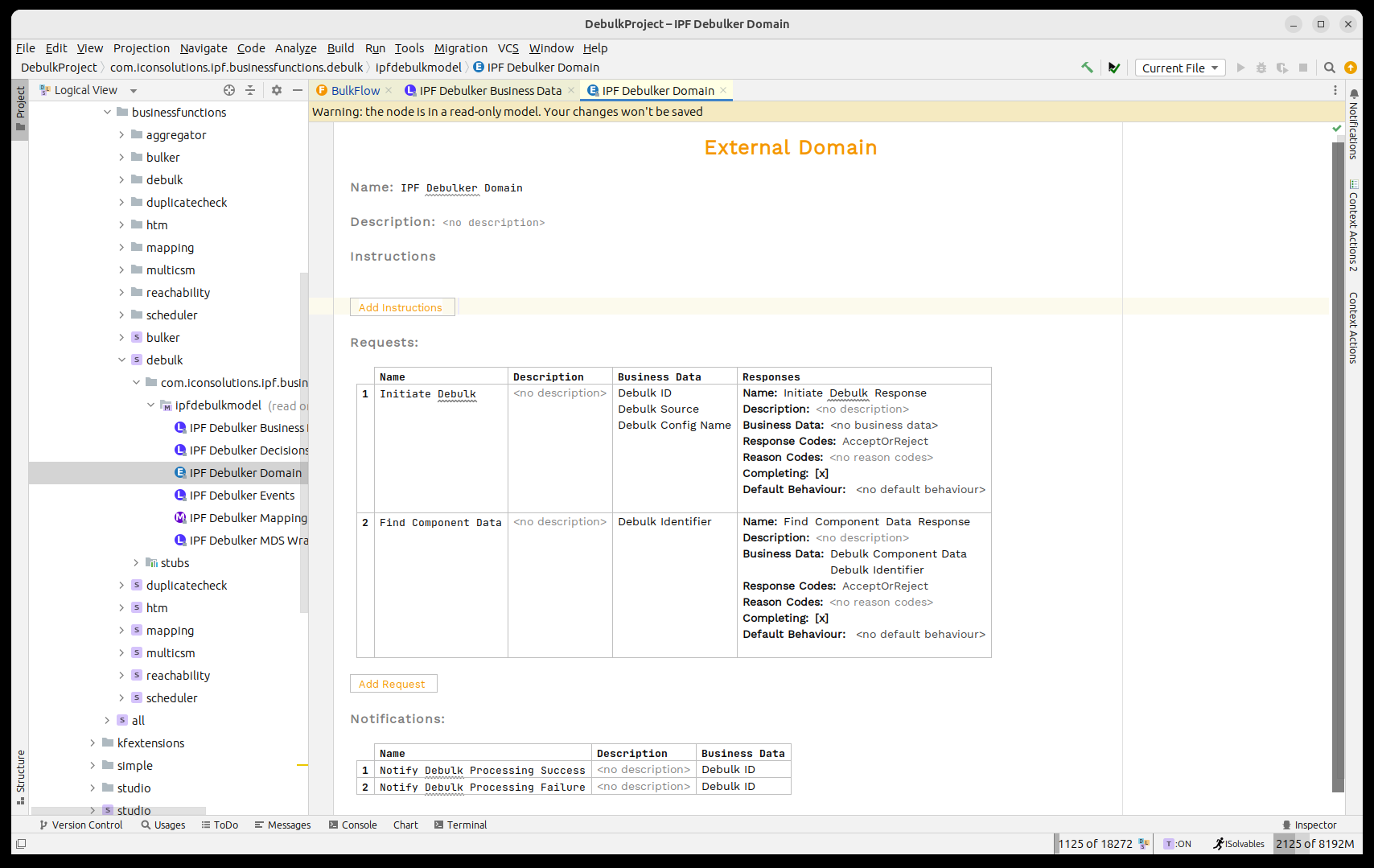
Así que, al igual que cualquier proceso normal, necesitamos llamar a este dominio. Para hacerlo, consideraremos los puntos de integración estándar:
-
Necesitaremos un estado para manejar mientras se está llamando al almacén del componente, lo llamaremos 'Debulking. También necesitaremos un estado para manejar el fallo, lo llamaremos 'Rechazado'.
-
El archivo puede desglosarse con éxito o fallar en la validación, por lo que necesitaremos dos eventos: 'Listo para Procesar' y 'Archivo Rechazado'.
-
Utilizaremos el evento 'Listo para Procesar' al recibir el 'Iniciar Debulk Respuesta' con el código 'Aceptado' y de manera similar utilice 'Archivo Rechazado' en el código 'Rechazado'.
-
Llamaremos al almacén de componentes al iniciar.
-
Cuando se genere el evento exitoso, nos moveremos a Completo; en caso de fallo, nos moveremos a Rechazado.
Procedamos a añadir todas estas capacidades.
Primero los estados y eventos:
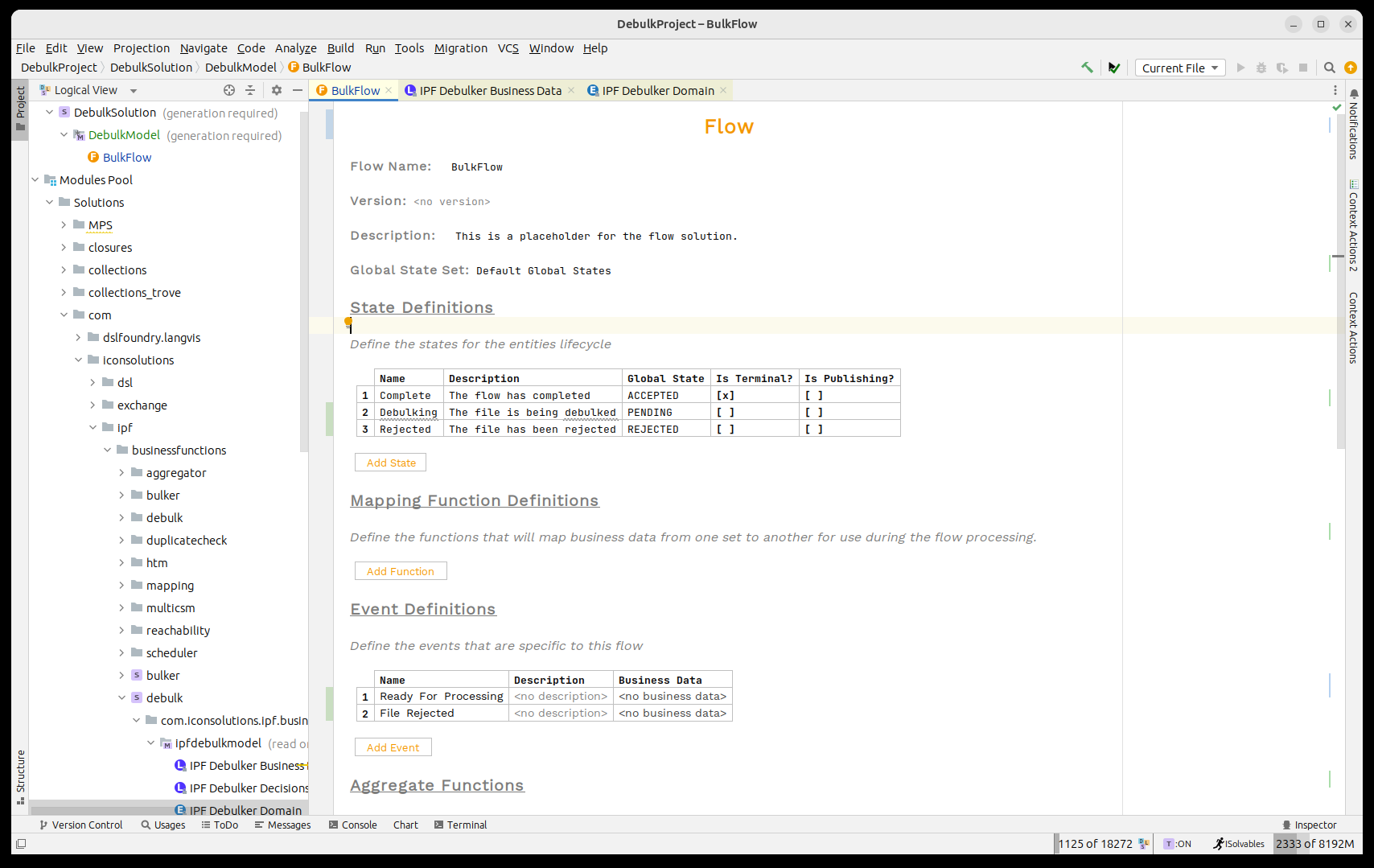
Y luego los comportamientos:
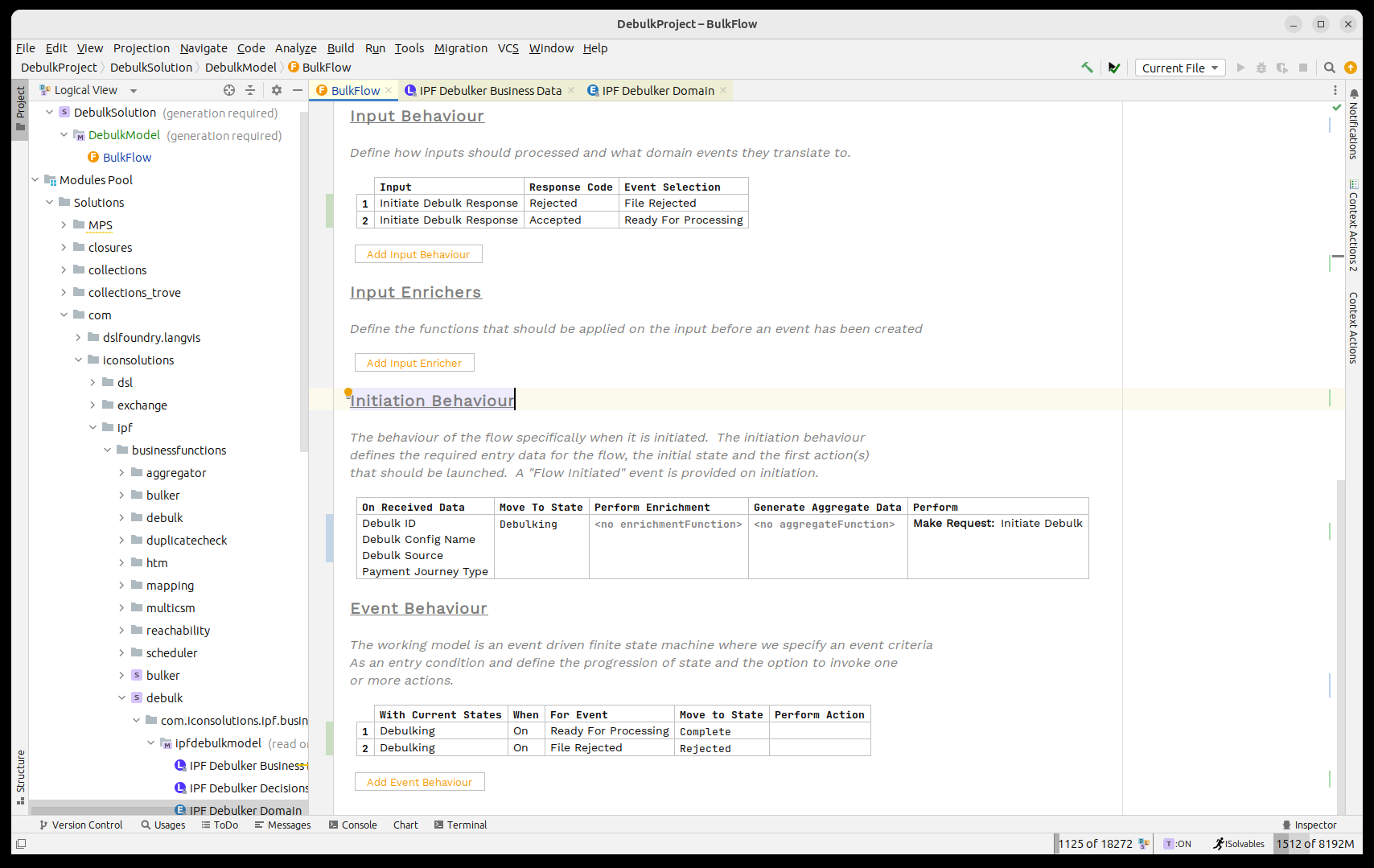
Ahora necesitamos pensar en cómo procesar el archivo despojado en el almacén de componentes.
Iniciar flujos a través del almacén de componentes es muy similar a iniciar flujos estándar. La única diferencia aquí es que podemos estar iniciando más de un flujo a la vez, dependiendo de cuántos registros haya en la entrada del almacén de componentes.
Para utilizar esto, necesitamos conocer dos cosas:
-
El marcador del almacén de componentes bajo el cual se encontrarán los registros secundarios.
-
El flujo que deseamos invocar.
En nuestro caso, el marcador es 'Document. CstmrCdtTrfInitn. PmtInf'- esto representa el punto en el pain001 donde se retienen las transacciones por lotes.
Para el flujo, crearemos un nuevo flujo de 'Lote'.
Creando el flujo 'Batch'
Así que antes de comenzar a editar el flujo masivo, vamos a crear la estructura para el flujo por lotes.
Para hacer esto, crearemos un flujo tal como lo hicimos anteriormente al crear el flujo masivo.
-
Se llamará 'Batch Flow'
-
Tomará en:
-
Identificador de despojo
-
Desglosar Datos del Componente
-
Tipo de Viaje de Pago
-
Relacionado Unit of Work
-
-
Tendrá estados terminales de publicación para:
-
Completo
-
Fallido
-
Antes de crear, vale la pena mencionar el nuevo elemento de datos comerciales aquí 'Relacionado Unit of Work. Este campo se utiliza para vincular los diferentes flujos de trabajo del conjunto.- es decir, para establecer la relación entre los flujos hijo y padre. Desde una perspectiva de procesamiento, no es necesario, y se publicará automáticamente por el proceso. Sin embargo, si falta, no podrá navegar entre los flujos utilizando la interfaz de usuario operativa.
Ahora añadamos todos los elementos a nuestro flujo:
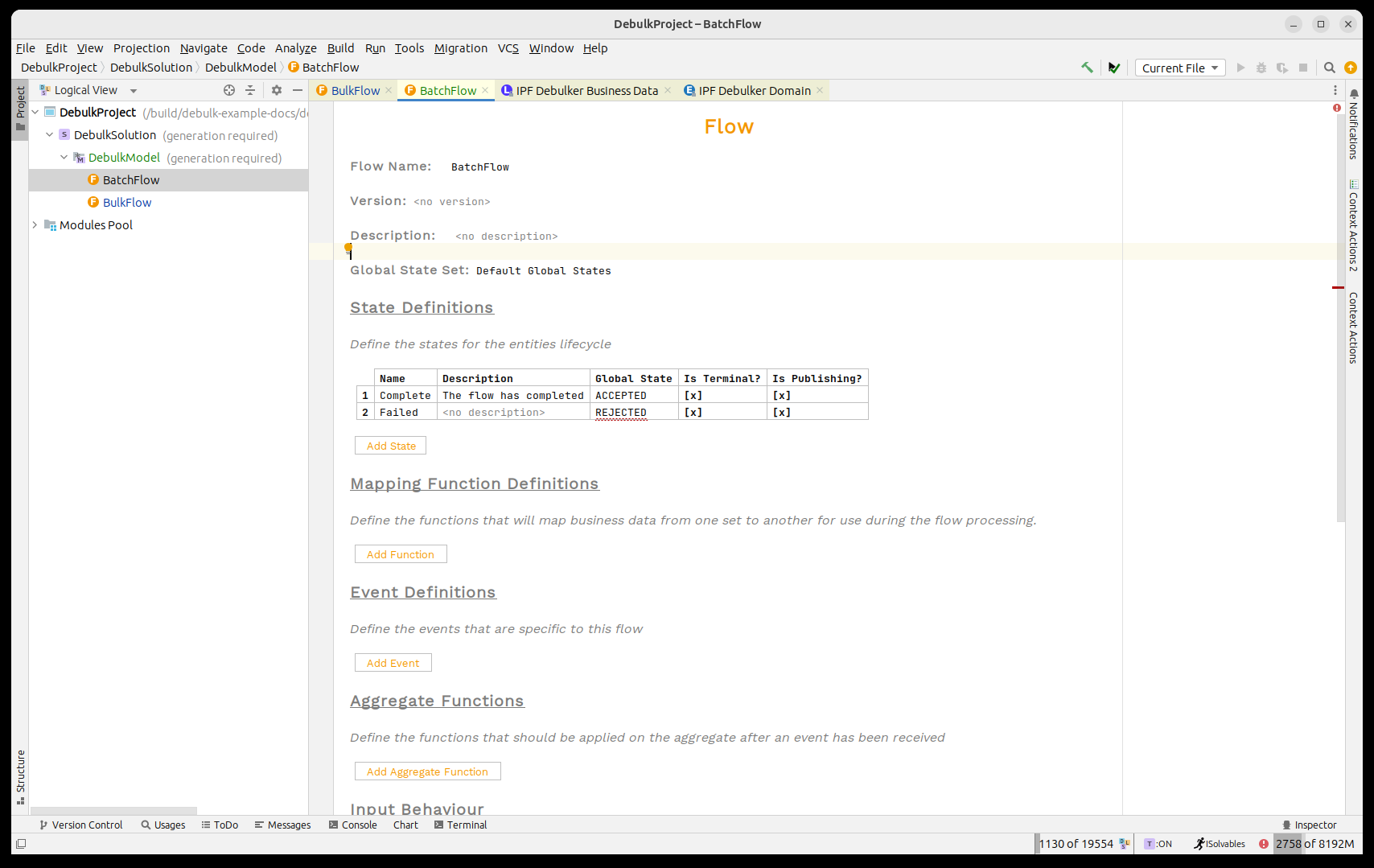
con la configuración de inicio:
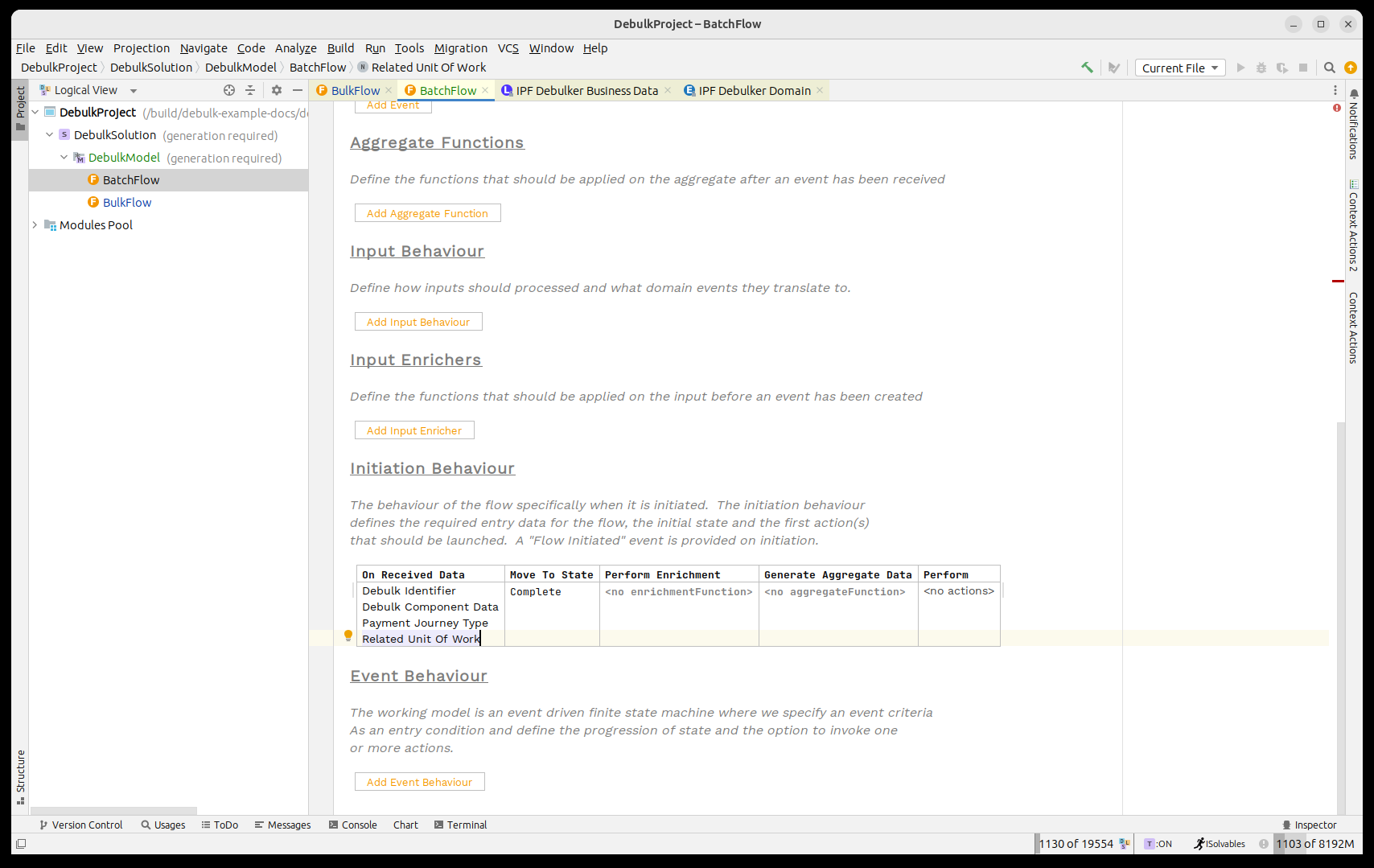
Esa es nuestra estructura de flujo por lotes definida, así que volvamos al flujo a granel y añadamos el inicio de nuestro proceso de desagregación.
Llamando al Flujo de Archivos
Así que para esto utilizamos el concepto de un 'Bulk Llamada de flujo. Funciona igual que una llamada de flujo normal, excepto que también requiere que indiquemos qué nivel del volumen necesita procesar.
Así que comenzaremos cambiando nuestro flujo para que, al recibir el evento 'Listo para Procesar', llamemos al 'Flujo por Lotes' para cada 'Document. CstmrCdtTrfInitn. PmtInf' elemento en el volumen.
Cambiemos el procesamiento ahora para que pasemos a un nuevo 'Flujo'. State'. Le daremos el identificador de 'Iniciar Flujo por Lotes' y luego en el cuadro 'Realizar Acción' llamaremos a nuestro 'Bulk Flujo' utilizando la capacidad de flujo masivo de llamadas. Finalmente, especificaremos el marcador como 'Documento'.
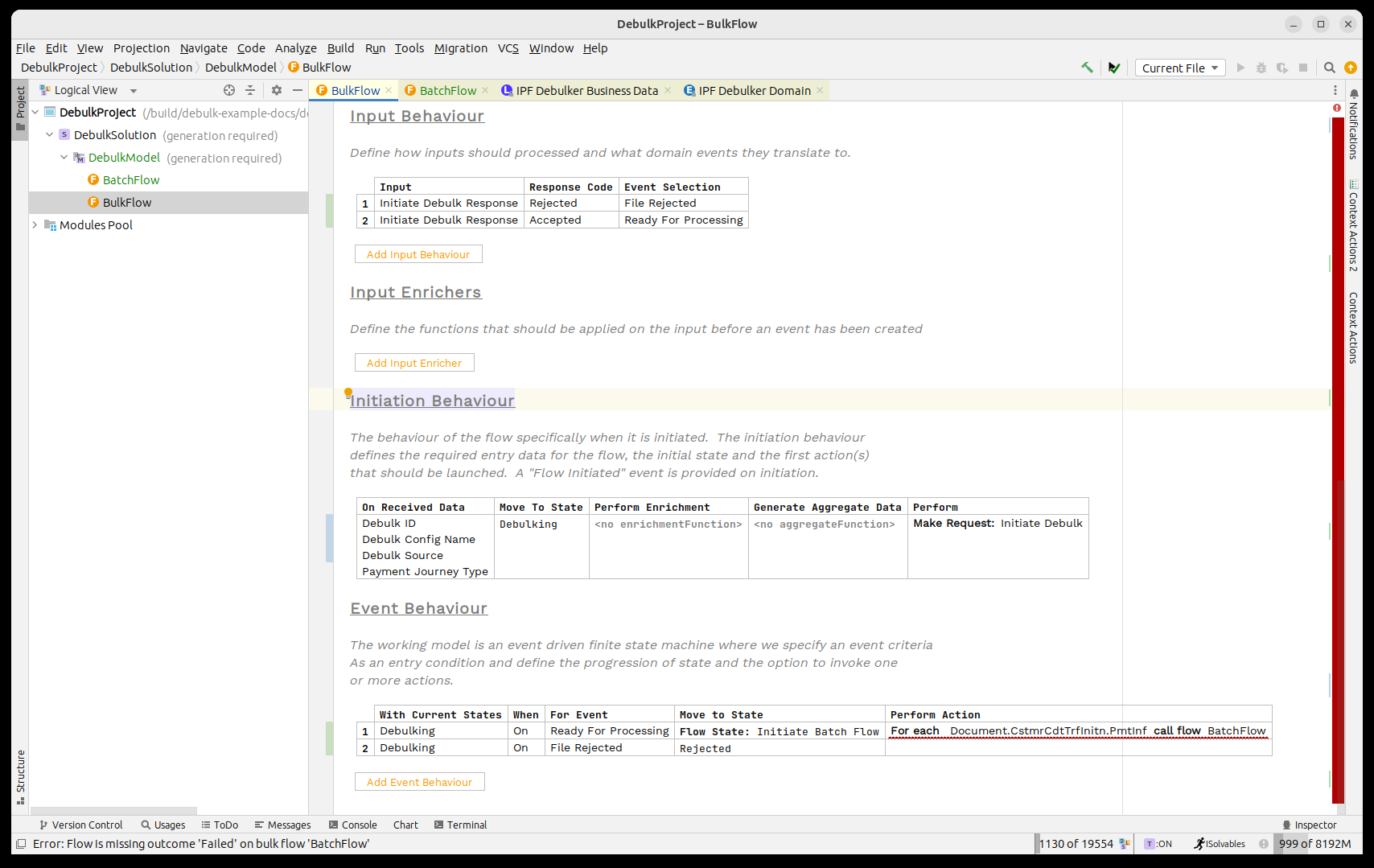
Al utilizar el 'Call Bulk Flow' capacidad invocaremos el almacén de componentes y luego se activará tantos flujos como necesitemos que coincidan con el marcador proporcionado.
Una vez que se haya invocado, devolverá un acuse de recibo para indicar que la solicitud ha sido aceptada.
Así que lo primero que necesitamos hacer es gestionar ese acuse de recibo. Regresa como un 'Bulk Tipo de evento 'Reconocimiento'. Para manejar esto, crearemos un nuevo estado 'Esperando Resultados' al que nos moveremos al recibir el reconocimiento; no realizaremos ninguna acción aquí, ya que luego esperaremos a que regresen nuestros resultados de flujo masivo.
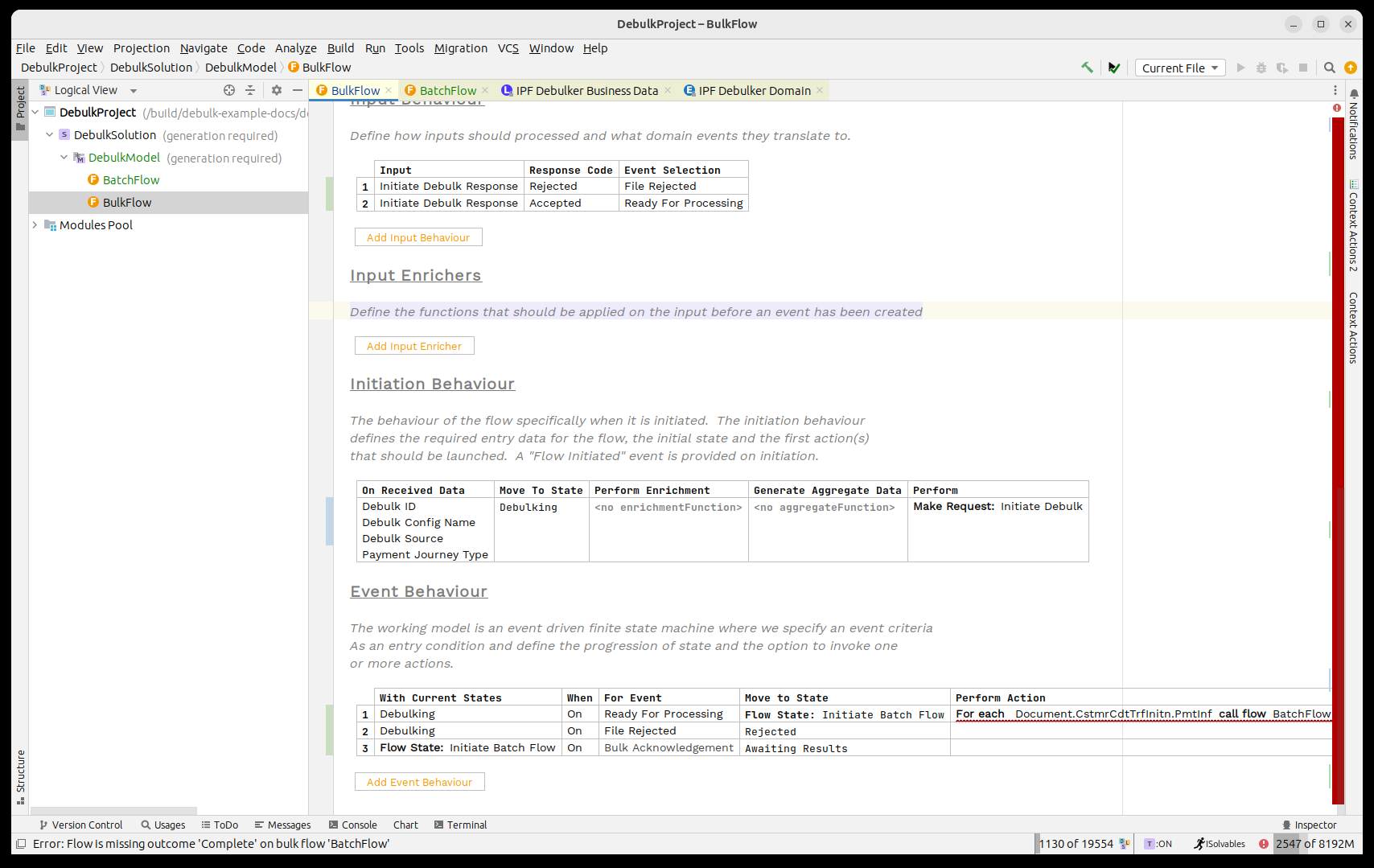
A continuación, necesitamos considerar los resultados de nuestros flujos de lotes secundarios que regresan. Para esto, utilizaremos la verificación de umbral para monitorear cuándo han regresado todos.
Así que primero, al recibir un resultado infantil, permanecemos en el mismo estado y llamamos a la verificación del umbral.
La función de Verificación de Umbral mantiene un conteo de los resultados que han regresado de los flujos secundarios; es configurable, pero por defecto asumirá que ha finalizado cuando TODOS los flujos hayan regresado con éxito y habrá fallado cuando un ÚNICO elemento haya fallado.
Entonces debemos manejar los tres resultados posibles; en nuestro caso, cuando uno de los eventos pasados es devuelto, procederemos a completar y si llega el evento de fallo, procederemos a rechazado.
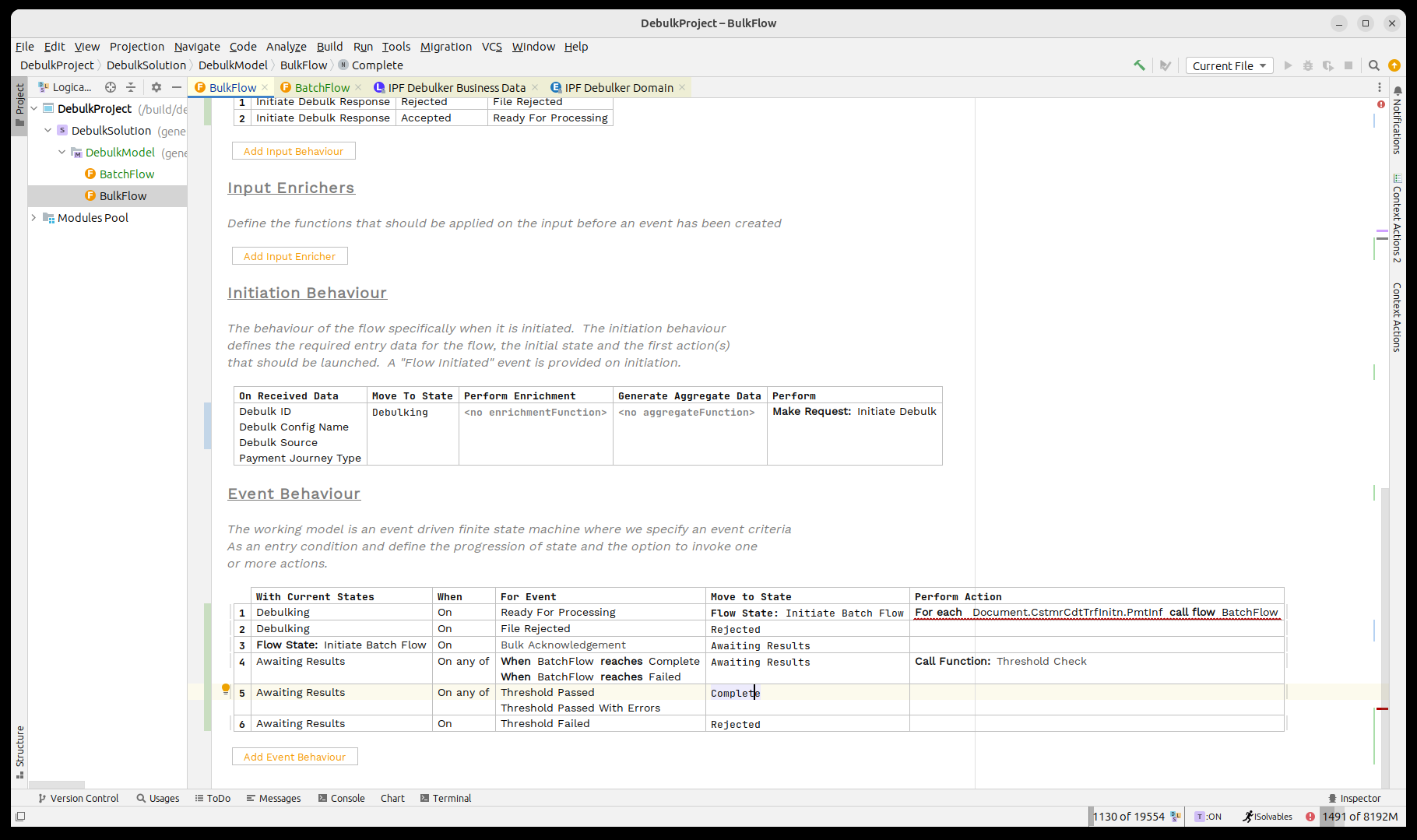
Finalmente, observamos que la llamada al flujo por lotes sigue apareciendo en rojo. Vamos a abrir el inspector para ello presionando CTRL ALT I.
Aquí necesitamos establecer el tipo de viaje para nuestro flujo secundario, en este caso 'BATCH' y luego utilizaremos el predefinido.mapping función 'Convert Debulker ID a Identificador' que mapeará nuestro 'ID de Debulk' en el formato de identificador relevante.
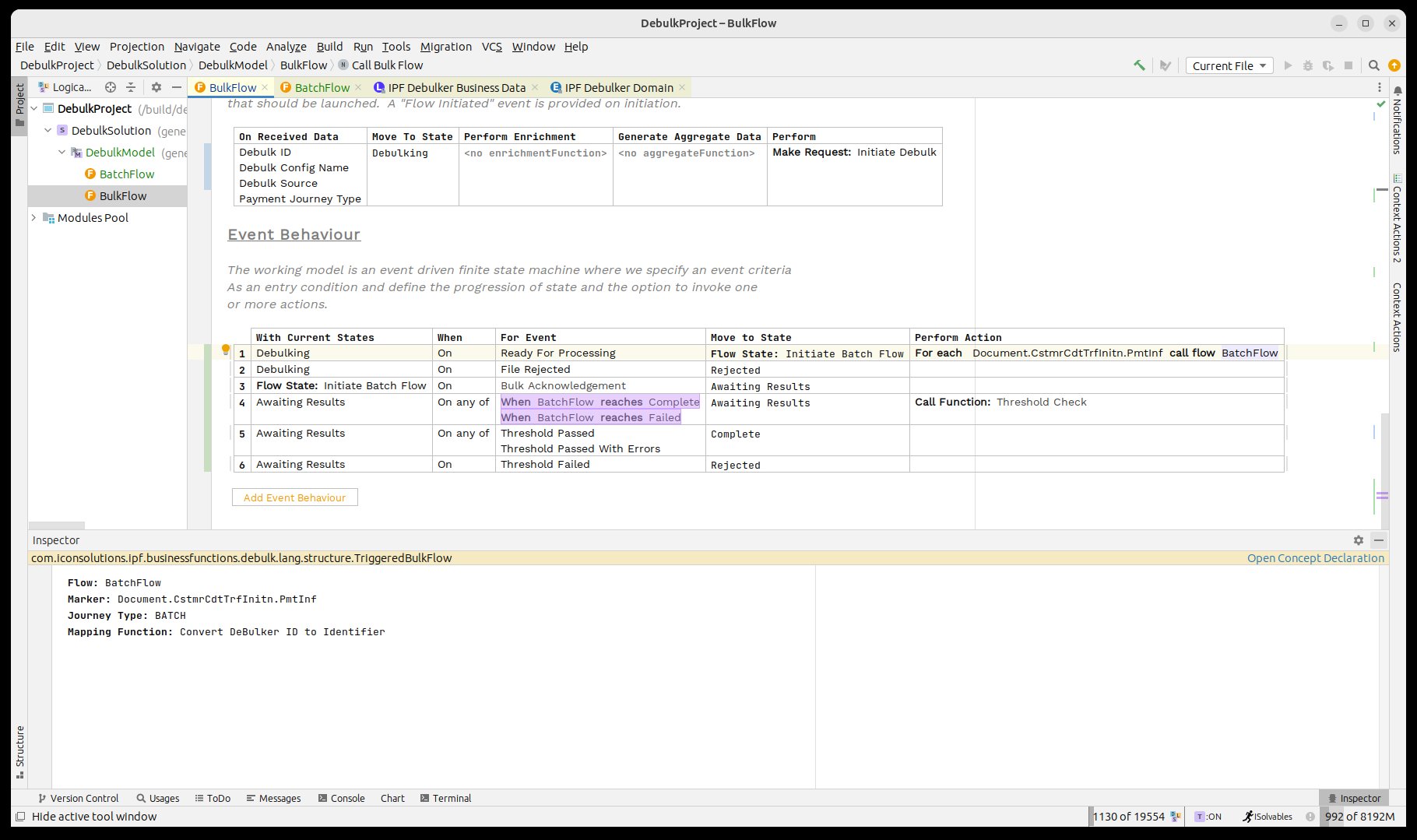
Eso es todo, ahora hemos completado la integración básica entre nuestros flujos de carga masiva y por lotes.
Ahora pensamos en cómo funcionará el flujo por lotes. Necesita llamar al siguiente nivel, el nivel de 'Pago'. Por lo tanto, nuevamente necesitamos crear un nuevo flujo.
Creando el flujo de 'Pago'
A continuación, crearemos un payment flow para manejar el nivel final de nuestro pain001.
En este caso, nuestro payment flow Dejaremos por ahora solo un flujo predeterminado simple que se completará de inmediato.
Desde una perspectiva de datos, tiene los mismos elementos que el flujo por lotes:
-
Identificador de desbaste
-
Desagregar Datos del Componente
-
Tipo de Viaje de Pago
-
Relacionado Unit of Work
Creemos este flujo ahora.
Implementando el flujo 'Batch'
Ahora podemos llamar al payment flow del flujo por lotes. El proceso es idéntico al que establecimos para el flujo a granel. Como recordatorio:
-
Al iniciar, realizaremos una llamada de flujo masivo a la payment flow y utilice el marcador 'Document. CstmrCdtTrfInitn. PmtInf. CdtTrfTxInf.
-
Cuando se reciba el acuse de recibo masivo, nos moveremos a un estado de 'Esperando resultados'.
-
Cuando los resultados de la payment flow se reciben, realizaremos la Verificación de Umbral.
-
Cuando se complete la verificación del umbral, pasaremos a Completo.
Ahora añadamos todo eso:
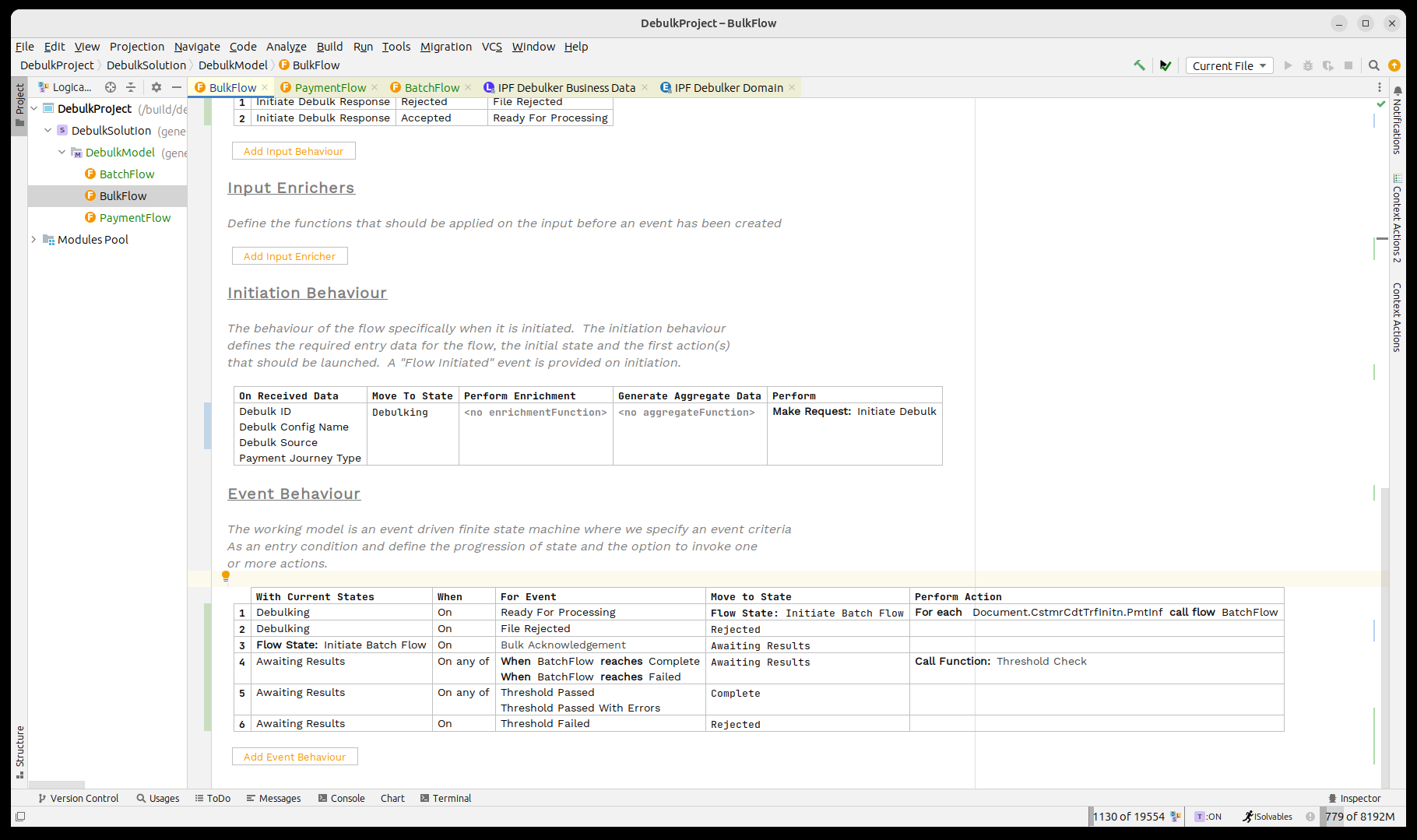
Finalmente, al igual que con los flujos anteriores, necesitamos definir el tipo de viaje del flujo secundario. Hacemos esto abriendo el inspector (presionando CTRL ALT I) y luego estableciendo el valor en 'PAYMENT'.
Eso es todo, ahora hemos completado nuestra implementación de DSL para la desagregación de nuestro pain001.
Java Implementación
El siguiente paso sería completar la parte de implementación de nuestro flujo.
Añadiendo dependencias
Ahora que hemos terminado de modelar nuestro proceso a granel, es momento de comenzar a trabajar en el lado de la implementación.
En primer lugar, necesitaremos agregar la dependencia para el cliente debulker en el proyecto de servicio.pom.xml.
<dependency>
<groupId>com.iconsolutions.ipf.businessfunctions.debulk</groupId>
<artifactId>ipf-debulker-floclient-service</artifactId>
</dependency>También eliminaremos el 'SampleController' del proyecto de aplicación ya que esto está destinado para su uso con archivos de transacción simples normales. Agregaremos un reemplazo más adelante.
Habiendo hecho eso, reconstruya el proyecto.
maven clean install -DskipTestsAñadiendo controladores de muestra
Ese es nuestro ejemplo listo para ejecutarse, pero antes de eso necesitamos determinar cómo iniciar un nuevo flujo. En el mundo real, hay muchas maneras diferentes en las que podríamos querer alimentar el proceso de iniciación, pero aquí simplemente crearemos un controlador de muestra que nos permita introducir transacciones.
Para hacer esto, comenzaremos creando un simple bean para representar nuestros campos de datos iniciales:
@AllArgsConstructor
@NoArgsConstructor
@Data
@Builder
public class SampleDebulkInstruction {
private String filePath;
private String fileName;
private String configName;
private String bulkId;
}Luego utilizaremos esto en una función de controlador estándar de Spring que llamará a la iniciación de nuestro flujo de archivos:
@RestController
public class FileController {
@RequestMapping(value = "/submit", method = RequestMethod.POST)
public Mono<InitiationResponse> submit(@RequestBody final SampleDebulkInstruction request) throws IOException {
final String processingEntity = "BANK_ENTITY_1";
final String unitOfWorkId = UUID.randomUUID().toString();
final String filePath = Optional.ofNullable(request.getFilePath()).orElse("/tmp/");
final String fileName = Optional.ofNullable(request.getFileName()).orElse(UUID.randomUUID() + ".xml");
final String configName = Optional.ofNullable(request.getConfigName()).orElse("pain.001.001.09");
final String debulkId = Optional.ofNullable(request.getBulkId()).orElse(UUID.randomUUID().toString());
if (request.getFileName() == null) {
// file not provided, so generate a dummy one.
generateFile(filePath, fileName, 2, 10);
}
return Mono.fromCompletionStage(DebulkModelDomain.initiation().handle(new InitiateBulkFlowInput.Builder()
.withDebulkID(debulkId)
.withDebulkConfigName(configName)
.withDebulkSource(DebulkerFileSource.builder().fileProvider("local").filePath(filePath).fileName(fileName).build())
.withPaymentJourneyType("BULK")
.withProcessingContext(ProcessingContext.builder().unitOfWorkId(unitOfWorkId).clientRequestId(debulkId).processingEntity(processingEntity)
.build())
.build())
.thenApply(done -> InitiationResponse.builder().requestId(request.getBulkId()).uowId(unitOfWorkId).aggregateId(done.getAggregateId()).build()));
}
private void generateFile(String filePath, String fileName, int batches, int transactionPerBatch) throws IOException {
var xmlMapper = ISO20022MessageModel.init().xmlMapper();
var generator = new Pain001Generator();
var doc = new Document();
doc.setCstmrCdtTrfInitn(generator.generate(batches, transactionPerBatch));
var xml = xmlMapper.toXML(doc);
File file = new File(filePath + fileName);
FileUtils.writeStringToFile(file, xml, StandardCharsets.UTF_8);
}
}Los puntos clave a tener en cuenta aquí son que llamamos a nuestro Debulk Dominio y simplemente pase los datos relevantes tal como lo hacemos en cualquier flujo de iniciación normal. También proporciona un generador de archivos para pain001, de modo que, si es necesario, se genere un nuevo archivo con fines de prueba.
Finalmente, dado que la tienda de componentes utiliza Kafka, necesitamos agregar nuestras propiedades predeterminadas de kafka.
common-kafka-client-settings {
bootstrap.servers = "localhost:9093"
}
akka.kafka {
producer {
kafka-clients = ${common-kafka-client-settings}
restart-settings = ${default-restart-settings}
kafka-clients {
client.id = ipf-tutorial-client
}
}
consumer {
kafka-clients = ${common-kafka-client-settings}
restart-settings = ${default-restart-settings}
kafka-clients {
group.id = ipf-tutorial-group
}
}
}
default-restart-settings {
min-backoff = 1s
max-backoff = 5s
random-factor = 0.25
max-restarts = 5
max-restarts-within = 10m
}También deberá incluir la configuración de debulking pain001.
Eso es nuestra implementación completada, ¡es hora de intentar ejecutar nuestro proceso masivo!
Ejecutando el proceso
Para que el proceso se ejecute, necesitamos acceso a Kafka y Mongo. Utilizaremos la configuración estándar para esto y ejecutaremos:
docker compose -f minimal.yml -f kafka.yml up -dUna vez que esté en funcionamiento, podemos simplemente iniciar nuestra aplicación como una aplicación estándar de Spring Boot. Una vez que esté en funcionamiento, lo más sencillo es generar un nuevo registro utilizando el pequeño controlador de muestra que creamos:
curl -X POST localhost:8080/submit -H 'Content-Type: application/json' -d '{}' | jqEntonces podemos verificar nuestra salida mirando en la aplicación de desarrollador:
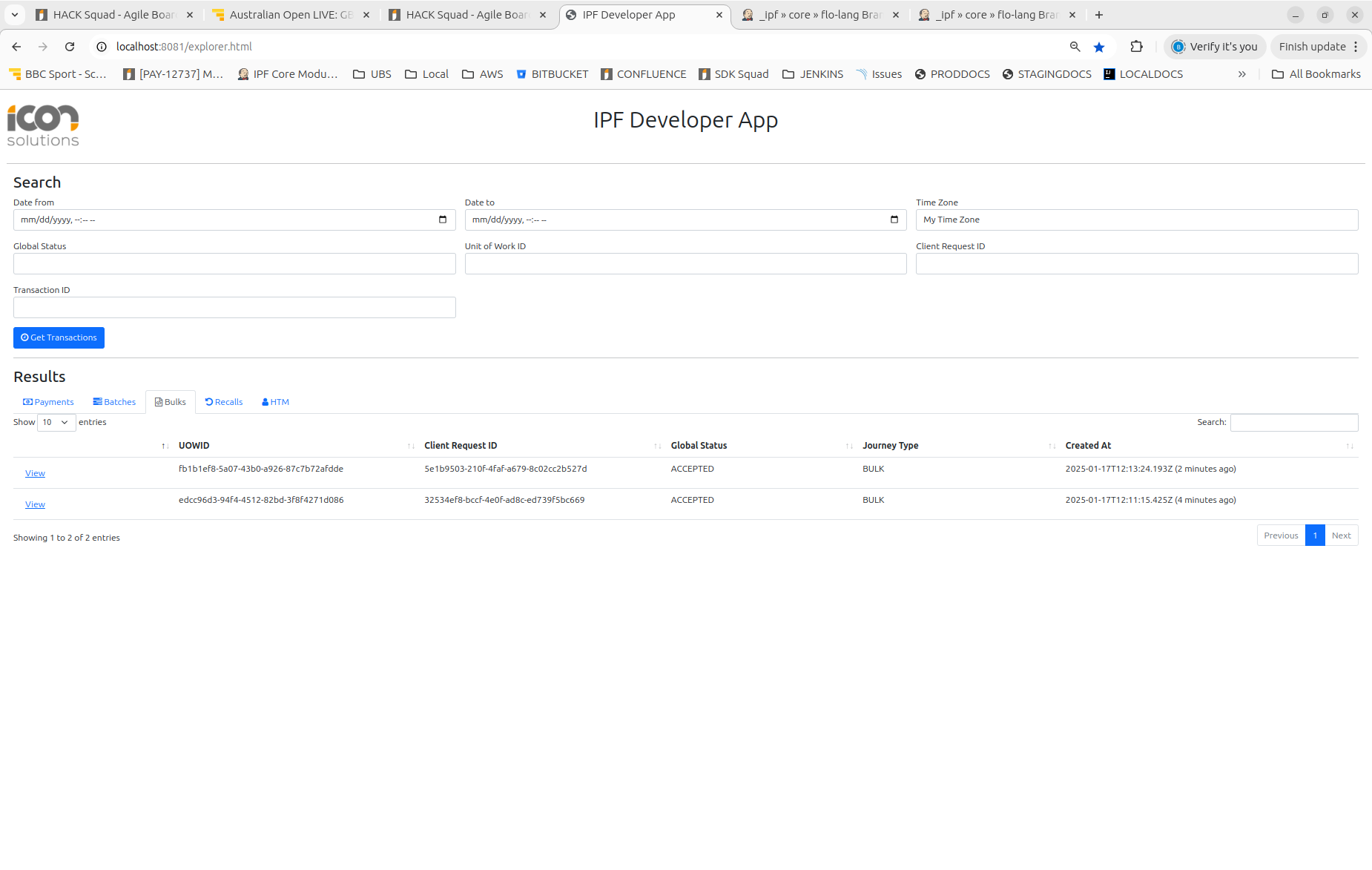
Aquí podemos ver los diferentes niveles del procesamiento: 'Pagos', 'Lotes' y Bulks.