Cómo implementar un debulk básico
Para completar esta guía, necesitarás lo siguiente:
-
Conocer tu versión actual de IPF
-
Conocer la versión adecuada del IPF Scaffolder
Crear el proyecto
Comenzaremos creando un nuevo proyecto como cualquier otro.
mvn com.iconsolutions.ipf.build:ipf-project-scaffolder-maven:<your-scaffold-version>:scaffold \
-DgroupId=com.icon.ipf \
-DartifactId=debulk-example-1 \
-DsolutionName=DebulkSolution \
-DprojectName=DebulkProject \
-DmodelName=DebulkModel \
-DincludeApplication=y \
-DflowName=BulkFlow \
-DipfVersion=<your-ipf-version> \
-DoutputDir=/build/debulk-example-1Una vez generado, construiremos el proyecto.
mvn clean install -DskipTestsEstructuraremos nuestro ejemplo de debulker usando un pain001 estándar como entrada. Lo trataremos como un conjunto de cuatro flows:
-
Un flow "File" para representar el manejo del archivo que llega.
-
Un flow "Bulk" para representar el sobre de nivel superior del propio pain001.
-
Un flow "Batch" para representar la parte de instrucciones del pain001.
-
Un flow "Transaction" para representar la parte de transacciones del pain001.
Ahora abramos el proyecto en MPS. Veremos que nuestro "File Flow" ya ha sido proporcionado.
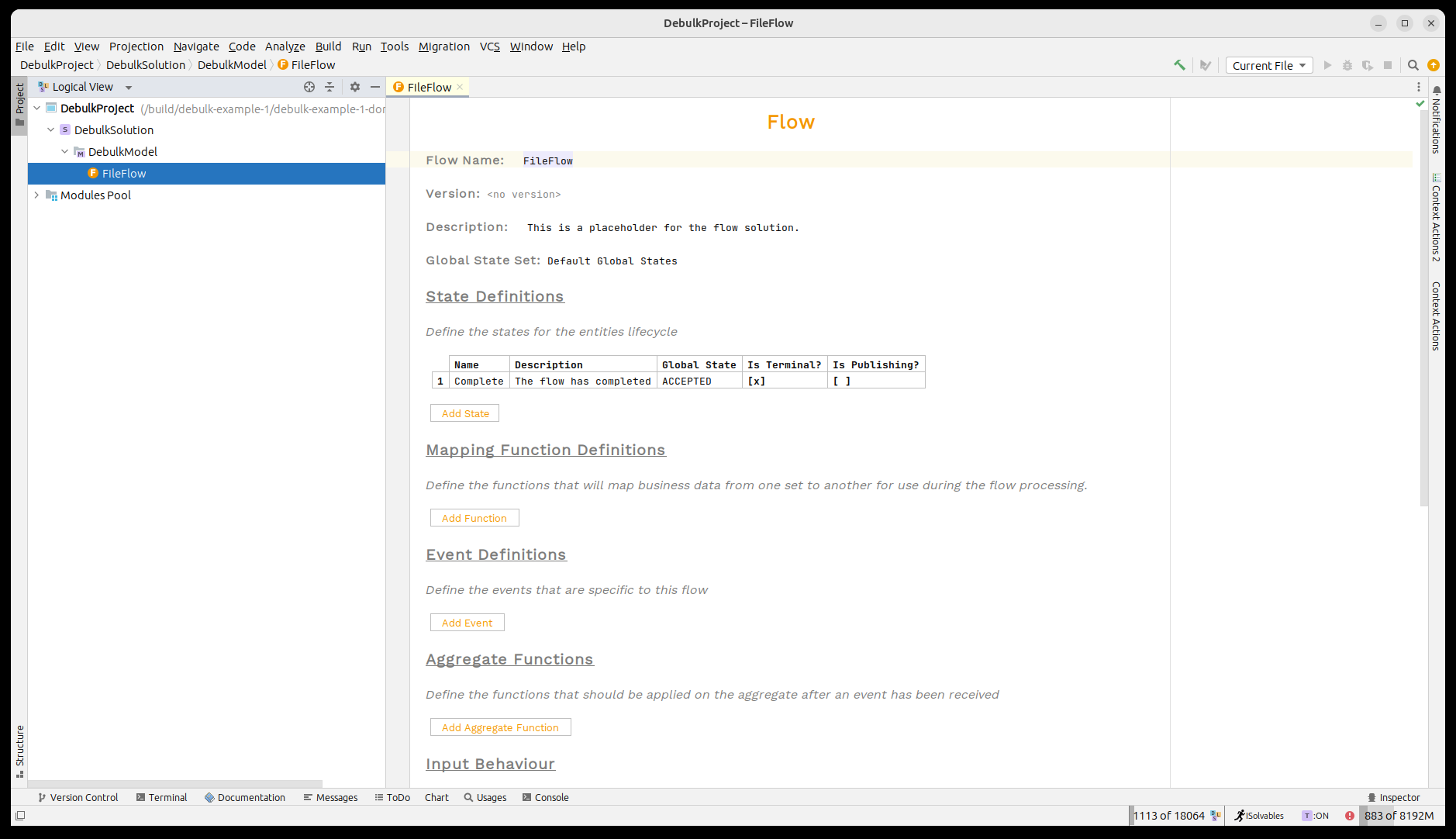
Un breve recordatorio sobre el IPF Component Store
El IPF component store se utiliza para hacer debulking de archivos grandes en componentes que luego pueden usarse dentro del sistema normal de flo. En nuestro caso, vamos a usar archivos pain001 y dividirlos en los diferentes niveles del archivo.
El component store requiere una configuración que le indique cómo dividir cualquier estructura de archivo que reciba. Esta configuración se proporciona en formato hocon; en el caso de pain001 se muestra a continuación un ejemplo:
ipf.debulker {
archiving.path = "/tmp/bulk_archive"
configurations = [
{
name = "pain.001.001.09"
splitter = "xml"
processing-entity = "BANK_ENTITY_1"
archive-path = "/tmp/bulk_archive"
component-hierarchy {
marker = "Document"
children = [
{
marker = "CstmrCdtTrfInitn.PmtInf"
children = [
{
marker = "CdtTrfTxInf"
}
]
}
]
}
}
]
}Los puntos clave a tener en cuenta aquí:
-
El nombre 'pain.001.001.09': cuando se reciba una instrucción para procesar un archivo, este nombre debe proporcionarse para indicar al component store que use esta configuración.
-
Cada nivel 'marker' representa los diferentes niveles de nuestro pain001 como se describió antes.
Modelar el proceso
Crear el flow "Bulk"
El flow bulk será responsable de recibir algún tipo de instrucción con detalles de dónde está almacenado el archivo pain001. Luego interactuará con el IPF component store para leer el archivo y hacer debulking en los componentes adecuados antes de iniciar el procesamiento de los flows de nivel superior.
Desde el punto de vista de la instrucción, el component store necesita que se proporcione la siguiente información clave:
-
Un ID único para el debulk: esto se modela mediante el elemento de datos "Debulk ID".
-
El nombre de la configuración a utilizar: esto se modela mediante el elemento de datos "Debulk Config Name".
-
La ubicación del archivo de datos: esto se modela mediante el elemento "Debulk Source".
Así que empecemos añadiendo esos tres elementos de datos como datos de iniciación en nuestro flow. Para hacerlo, primero necesitamos importar la librería de business data del debulker. Esto puede hacerse pulsando CTRL+R dos veces y buscando 'IPF Debulker Business Data'.
Una vez hecho, deberíamos ver algo como:
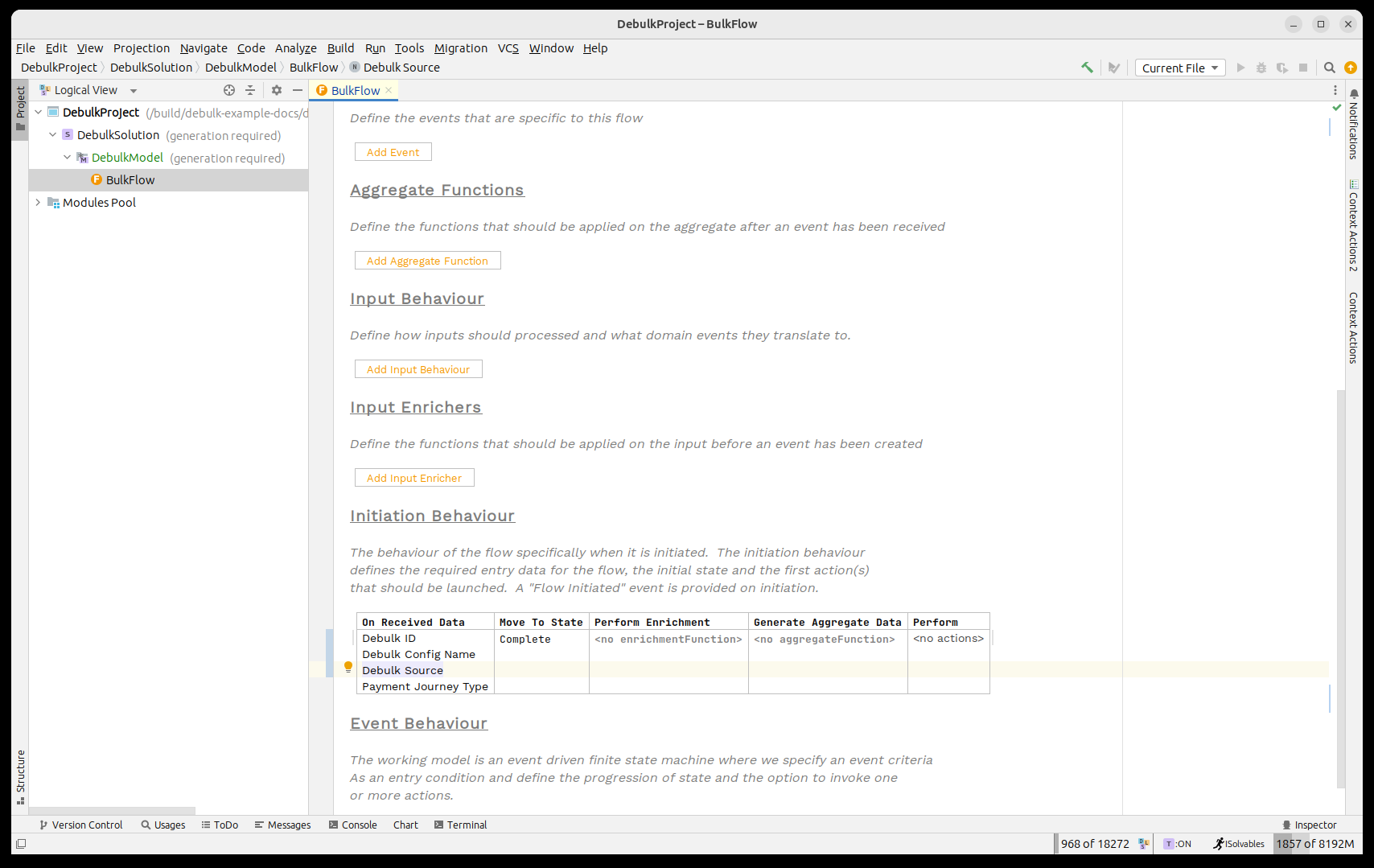
| Aquí estamos usando los data points directamente, pero es perfectamente razonable absorber tu propio tipo de archivo y luego usar una función de agregación para extraer los campos de IPF requeridos. |
A continuación, necesitamos invocar el 'IPF Component Store' para procesar el archivo bulk. El component store ha sido modelado como el 'IPF Debulker Domain'. Este tiene disponible la función 'Initiate Debulk' que toma los tres campos que hemos puesto a disposición e iniciará el procesamiento del archivo como resultado.
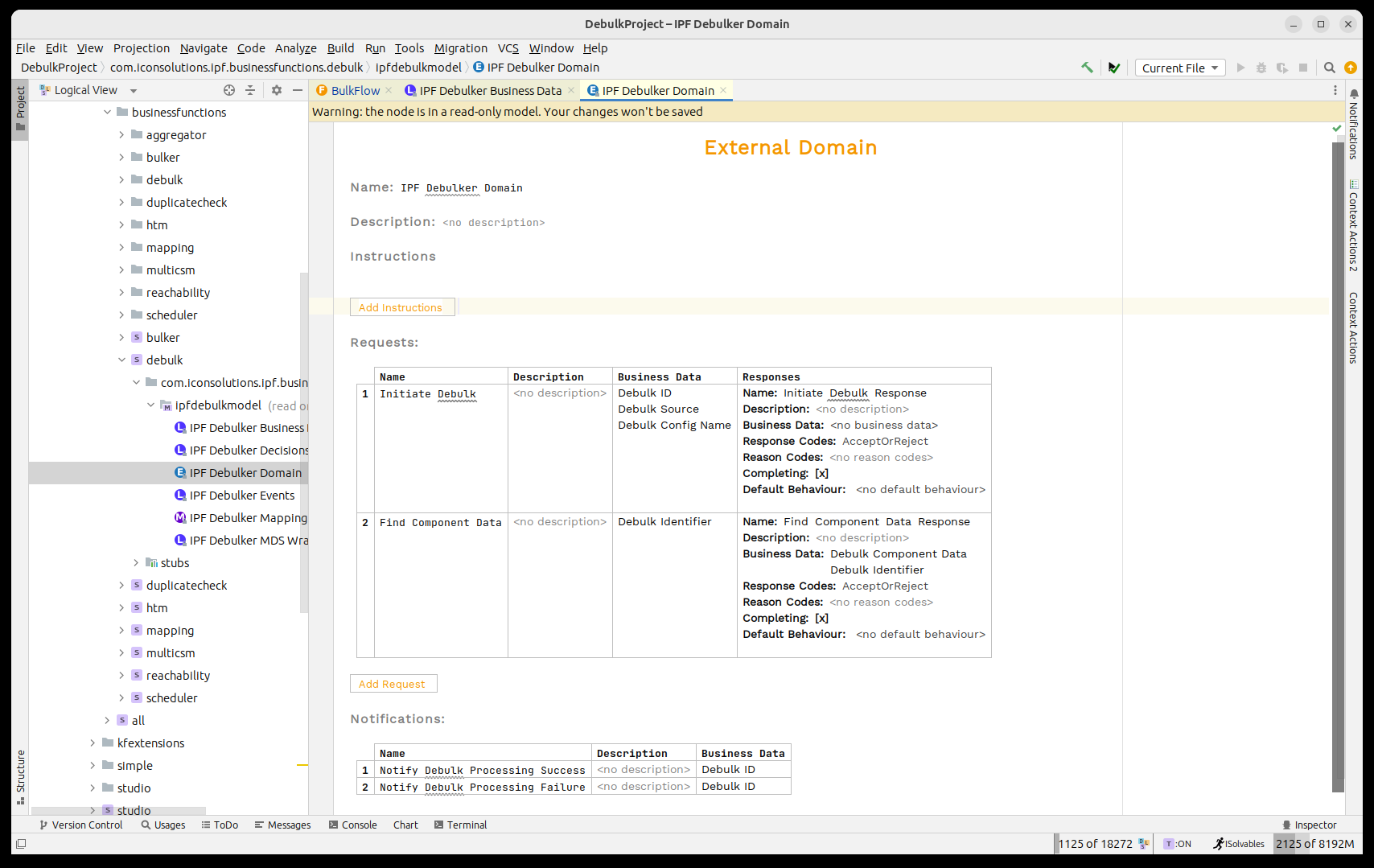
Así que, como en cualquier proceso normal, necesitamos llamar a este dominio. Para ello pensaremos en los puntos de integración estándar:
-
Necesitaremos un estado mientras se llama al component store; lo llamaremos 'Debulking'. También necesitaremos un estado para manejar fallos; lo llamaremos 'Rejected'.
-
El archivo puede hacer debulking con éxito o fallar la validación, así que necesitaremos dos eventos 'Ready for Processing' y 'File Rejected'.
-
Usaremos el evento 'Ready for Processing' al recibir la 'Initiate Debulk Response' con el código 'Accepted' y, de forma similar, usaremos 'File Rejected' con el código 'Rejected'.
-
Llamaremos al component store en la iniciación.
-
Cuando se emita el evento de éxito pasaremos a Complete, en caso de fallo pasaremos a Rejected.
Crear los flows hijo
Con el flow bulk en su lugar, podemos añadir los flows 'Batch' y 'Transaction'. Estos se iniciarán usando 'Call Bulk Flow' desde el flow bulk, especificando el marker apropiado para cada nivel:
-
Para 'Batch': marker 'CstmrCdtTrfInitn.PmtInf'
-
Para 'Transaction': marker 'CdtTrfTxInf'
El uso de 'Call Bulk Flow' para cada nivel activará instancias hijo por cada componente recuperado desde el component store.
Procesamiento en el flow hijo
Dentro de cada flow hijo, los dos datos clave estarán disponibles cuando se llamen como parte del proceso bulk:
-
Debulk Identifier
-
Debulk Component Data
El 'Debulk Component Data' contiene la representación String del fragmento de datos para ese nivel, y puedes convertirlo o mapearlo a tus estructuras según corresponda.
Comprobaciones de umbral entre padre e hijos
A medida que los flows hijo completan, a menudo es necesario que el flow padre determine cuándo todos han finalizado. Para esto, usa las comprobaciones de umbral descritas en Comprobaciones de umbral. Configura el porcentaje requerido usando la propiedad correspondiente si no es el 100%.
Resumen
En esta guía hemos:
-
Creado un proyecto con el scaffolder de IPF.
-
Configurado el component store para un pain001 típico.
-
Modelado un flow 'Bulk' que inicia el debulking y maneja los resultados.
-
Llamado a flows 'Batch' y 'Transaction' usando 'Call Bulk Flow'.
-
Usado el 'Debulk Identifier' y el 'Debulk Component Data' en los flows hijo.
-
Considerado las comprobaciones de umbral para coordinar la finalización.