IPF Persistent Scheduler
Introducción
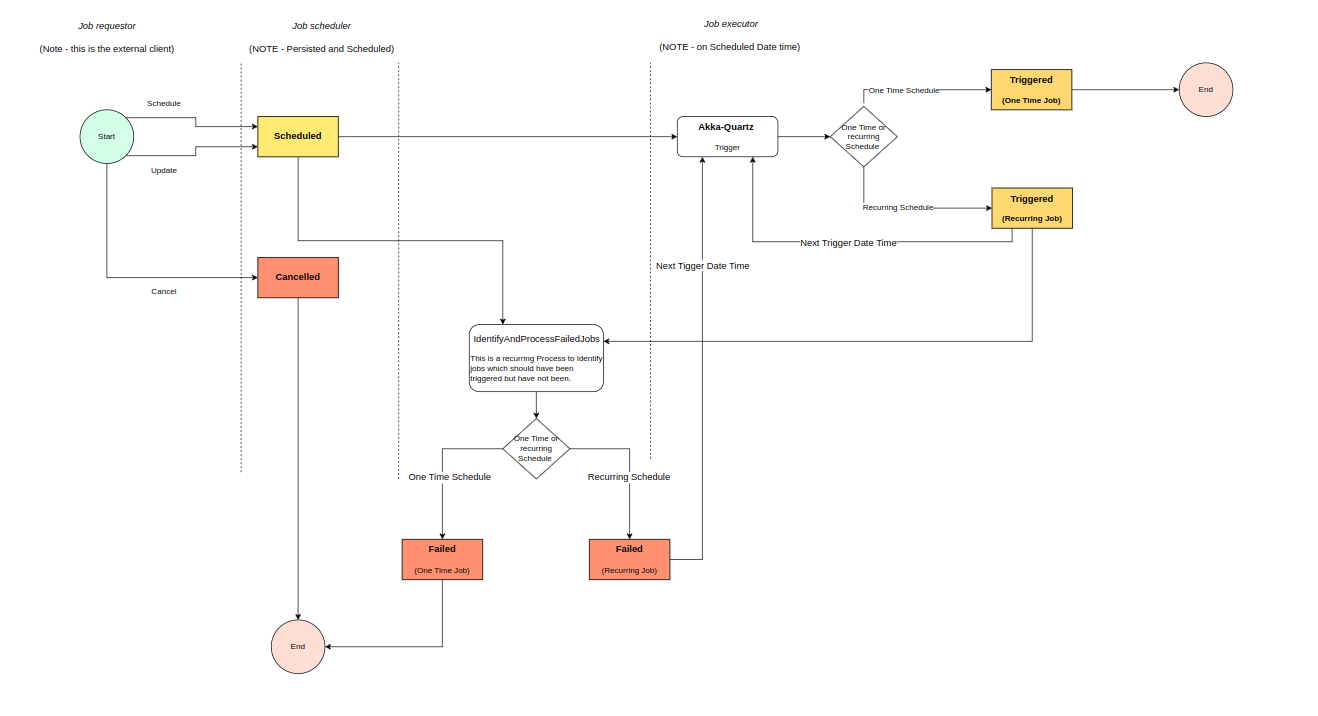
El IPF Persistent Scheduler le permite programar trabajos de cualquier tipo.
Está basado en el Quartz scheduler y admite dos tipos de programación de trabajos:
-
Recurrent jobs: definidos mediante expresiones cron, que son temporizadores especializados que definen puntos en el tiempo para la ejecución recurrente de tareas.
-
One-time jobs: definidos usando un objeto de Java
LocalDateTimeoInstantpara una programación de ejecución única con precisión de milisegundos.
El scheduler también admite calendarios, que pueden usarse para excluir ciertos bloques de tiempo de la programación. Esta configuración permite la ejecución flexible de trabajos únicos y recurrentes. También cuenta con una capa de persistencia, lo que significa que los trabajos se guardan en una base de datos, por lo que incluso si una aplicación falla o se reinicia, los trabajos previamente programados se recuperan y continúan su ejecución según lo previsto.
El Scheduler incluye mecanismos de seguridad, como un módulo de reprogramación que se ejecuta durante el arranque. Este módulo restaura todos los trabajos previamente programados en Quartz después de una falla. Para trabajar con el Scheduler, comience con la SchedulingModuleInterface.
Finalmente, el persistent scheduler está diseñado para ejecutarse en un Akka Cluster para garantizar que los trabajos se programen en todo el clúster y puedan sobrevivir a cualquier número de fallas de nodos (incluido un apagón total). Ciertos aspectos como la rehidratación de trabajos (que significa recargar trabajos tras una falla) y el procesamiento de trabajos fallidos se ejecutan en un Cluster Singleton para evitar el procesamiento duplicado en estos escenarios.
La arquitectura del scheduler se muestra a continuación: