Ingestion Service
ODS consumes IPF Processing Data from Kafka, transforms it into the ODS data model, and persists to the database.
Data related to a payment arrives with a processing context composed of
-
unitOfWorkId- groups all the data for a single payment/unit of work -
associationId- identifies the flow from which the data originated -
clientRequestId- the original client request id for the payment/unit of work -
processingEntity- groups payments under different entities
The general high-level flow for IPF processing data to persisted ODS data is:
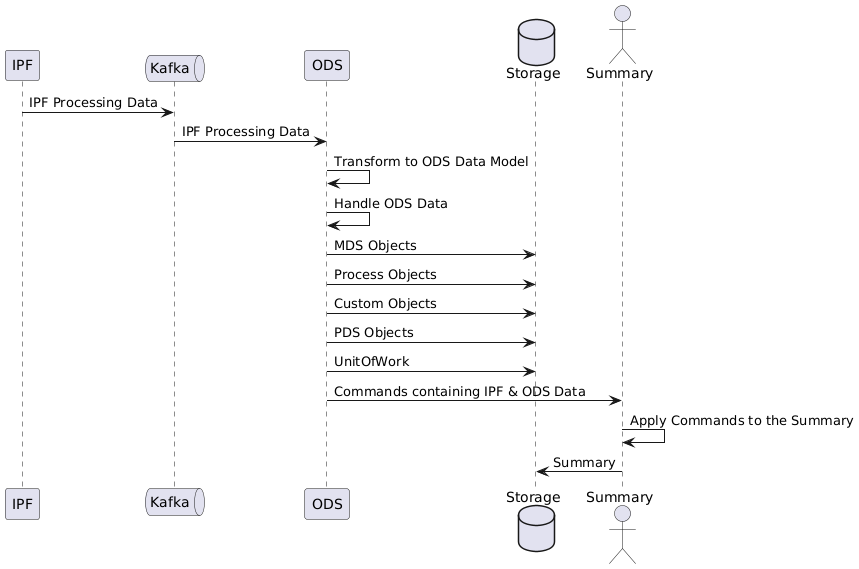
UnitOfWork
A single UnitOfWork is persisted to the database for each unitOfWorkId that is processed by IPF, this serves as meta-data for a given unitOfWork.
Process Flow Event timestamps are persisted into the UnitOfWork objects, and are used to identify the start and end of a unitOfWork lifecycle.
Summary
Some of the persisted ODS data is published to a payment summary actor, which applies the data in turn to create/update a persisted summary view.
The data is mapped into summary fields, as described in the Summary Mapping page.
Supported Data Types
The supported data types for data belonging to a payment is broken down into four categories, mds, pds, process, and custom.
MDS Objects
MDS objects are those that originate from ISO 20022 objects - for example a pain.001 instruction contains a group header, one or more instructions, and within each instruction, one or more credit transfer transactions. Each is considered a distinct MDS object, that belongs to the original payment or unit of work. When a pain.001 is received by an IPF processing flow, it is broken into parts, and all those parts are published to ODS in a single message.
PDS Objects
PDS objects are either IPF defined types, e.g. Csm, or JourneyType, or they are client defined custom types. A unit of work can have only a single PDS object by name, and tracks different versions of that object with a sequence number.
The greatest sequence number of all versions of a specific PDS object, is considered the "latest" version of that object.
Duplicate PDS objects, where the name and sequence number are the same for a given unit of work, are ignored.
Process Objects
Process objects are those that originate around the processing of a payment, for example a process object is produced for each message exchanged with another system by the IPF processing flow.
Process objects are assigned a unique identifier by default, which is composed of the "primary association" and a randomly generated uuid. This unique ID is used by ODS to determine if process objects have been seen before. For example, if an object is published more than once, or is consumed more than once, then only a single instance will exist in the database provided the received objects have the same unique ID.
Custom Objects
| Custom objects are no longer ingested by ODS, but attachments are still supported and stored in the custom objects collection. |
Custom objects represent data belonging to a payment that isn’t an ISO 20022 MDS object, or a process object. It is likely that this object will contain customer-specific payment related data.
Custom data objects are usually key/value pairs.
Versioning
ODS maintains backwards compatibility with the schema version of IPF Processing Data produced by IPF. The following table outlines the versions.
| Version | Compatibility |
|---|---|
1 |
Supported but deprecated |
2 |
Supported |
Bulk Writes
ODS Ingestion utilises bulk write commands when inserting documents into the database. The number of documents being inserted in a single command is dependent upon the number of Data Envelopes supplied by IPF Processing Data Ingress to ODS Ingestion’s BatchedIpfProcessingDataHandler implementation.
For optimal Ingestion performance, you may need to tune the Ingress configuration. See the Ingress tuning batch configuration documentation for more details.
Metrics are enabled by default to monitor the number of documents being inserted per database command, these should be used alongside the Ingress metrics to tune ODS Ingestion performance. These can be disabled by configuring ods.metrics.enabled = false.
When enabled, the following metrics will be emitted:
| Metric name | Possible tags | description |
|---|---|---|
|
type → "MDS", "PDS", "PROCESS", "UNIT_OF_WORK", "SUMMARY" |
A summary metric that records the number of documents being written in a single insert command. |
|
type → "MDS", "PDS", "PROCESS", "UNIT_OF_WORK", "SUMMARY" |
A counter metric designed to track the occurrence of duplicate key exceptions during document insertion. In the context of the MDS, PDS, and Process collections, these exceptions are disregarded, considering their append-only nature. However, any such exceptions for the UnitOfWork and Summary collections trigger appropriate document updates |
Summary Identity Enrichment Housekeeping Task
A Akka Cluster Singleton is used to execute a recurrent housekeeping task that enriches Payment Summary identification fields (debtorAccount, debtorAgentBIC, creditorName, etc…) using the information present on the Payment’s related Batch Summary.
This enables ODS Inquiry to search for these Payments using the Batch identification information, which was previously not present on the Payment.
This functionality must be explicitly enabled through config, the full configuration options can be found below.
This job will only update Payments that are related to a Batch AND have identification information different to the related Batch.
|
The values present on the Batch Summary are considered as the source of truth for these identification fields. When this functionality is enabled, any existing identity field values on a Payment Summary will be overridden by the values from its related Batch Summary. This only applies to Payment Summaries that have a related Batch Summary, associated via the Payment’s persisted |
The targeted identification information fields are:
-
debtorAccount -
debtorName -
debtorBIC -
debtorAgentBIC -
creditorAccount -
creditorName -
creditorBIC -
creditorAgentBIC
The general high-level flow for this housekeeping task is:

Default Configuration
The rate of execution for this housekeeping task can be controlled by configuring ods.persistence.housekeeping.summary.identity-enrichment.frequency. By default, this frequency is set to trigger the enrichment functionality every 10 seconds.
| This enrichment logic is designed for eventual consistency in ODS Inquiry API queries. As a result, the rest of the ODS Ingestion processing does not depend on its immediate completion. |
Full default configuration details are provided below:
ods.persistence.housekeeping {
summary.identity-enrichment {
# Configure to true if Summary Enrichment functionality is required
enabled = false
# How long to wait once ODS has started before making the first call to the Identity Enrichment job
initial-delay = 1M
# How often to call the Identity Enrichment job
frequency = 10s
# The Restart Strategy settings for the Identity Enrichment Akka Singleton
restart-settings {
# Minimum (initial) duration until the child actor (Identity Enrichment) will be started again, if it is terminated
min-backoff = 1s
# The exponential back-off is capped to this duration
max-backoff = 1s
# After calculation of the exponential back-off an additional random delay based on this factor is added, e.g. 0.2 adds up to 20% delay. In order to skip this additional delay pass in 0.
jitter-factor = 0.2
}
}
}| Enricher Enabled? | Reasoning |
|---|---|
When enabled (true) |
|
When disabled (false) |
|
|
When enabled, the enricher identifies Batch Summaries requiring enrichment by checking the existence of the
|
Error Handling
Due to the nature of the enrichment implementation, errors are retried naturally by the next recurrent execution.
Any errors thrown within the identification enrichment execution are logged as a warning with no action taken. The enrichment operations will be executed again shortly and Payments that failed to be enriched previously will be picked up in subsequent executions.